前言
搭建OpenAI gym环境的目的是为了后面的一系列DRL的强化学习代码的实现,因为OpenAI gym提供了很多的环境,并且训练较快,不用耗很长时间才能看到效果,因此是一个不错的环境。
我已经在gazebo中基于ardrone实现了一个关于DQN算法的验证,由于机器性能及其他的原因,耗时很长。并且也在airsim中做了一个简单的DQN实验训练,训练结果很好。但是也正是由于目前只会DQN的算法,而其他的DRL算法不会,因此才搭建该环境用于编写DRL算法,以进一步加深自己的理解。
一、安装gym环境
我这里采用的是pip方式安装,当然也可以git源码进行安装
1 | sudo pip install gym |
二、简单测试
coding:
1 | #!/usr/bin/env python |
输出:
1 | ('action_space', Discrete(2)) |
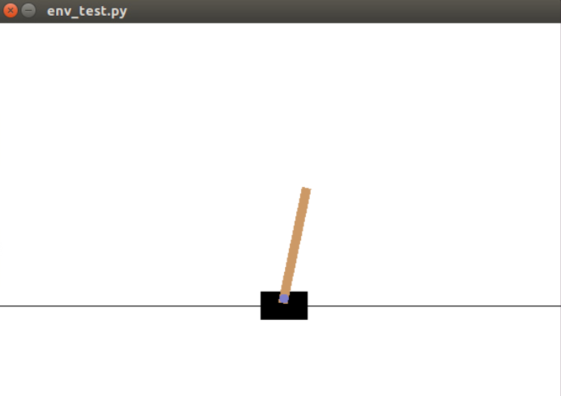
三、带返回值的测试
coding:
1 | #!/usr/bin/env python |
最后部分输出:
1 | ('observation', array([ -11.94872903, -0.1539066 , -130.92118709, -11.77476314])) |
四、保存训练视频
前提:需要安装一些依赖库,否则会报错
1 | sudo apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig |
coding:
1 | #!/usr/bin/env python |
运行完后,会在同级目录生成一个CatPole-experiment-1的文件夹,文件夹里的文件内容如下:
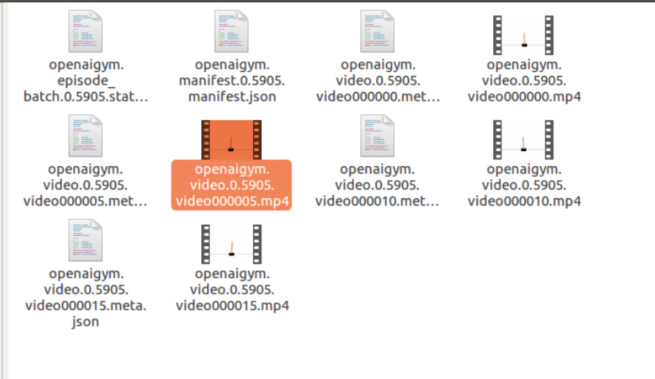
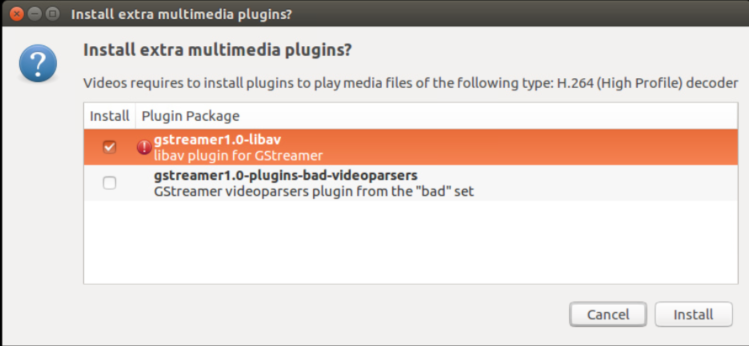
打开其中的MP4时,提示无法打开,然后按照提示默认安装即可
注意:
- video_callable=lambda episode_id: episode_id % 5 == 0:是每隔5秒保存一次,因此文件夹中有4个MP4视频,但是每个视频都很短暂,每个episode保存视频的话,参考这里
- force=True:是每次运行代码时,将之前生成的json文件和MP4文件直接覆盖掉
目前对这些json文件什么的还不是太清楚,总之是能保存一些训练的视频的。
总结
这部分主要是做一个OpenAI gym的环境安装及简单测试,并且测试的代码能够看到图形和实际运动的效果即可。后面将开始DRL的代码编写。