前言
主要参考莫烦大神的代码,对OpenAI gym的CartPole环境进行算法验证,所用算法为2015版本的Nature DQN。全部代码
一、CartPole说明
下图中的动态图没有显示出来,详细信息,点击CartPole-V0

杆通过未致动的接头连接到推车,推车沿着无摩擦的轨道移动。通过向推车施加+1或-1的力来控制系统。钟摆开始直立,目标是防止它倒下。每个时间步长都会提供+1的奖励,以保持杆保持直立。当极点与垂直方向相差超过15度时,该episode结束,或者推车从中心移动超过2.4个单位。
CartPole的详细说明:wiki介绍
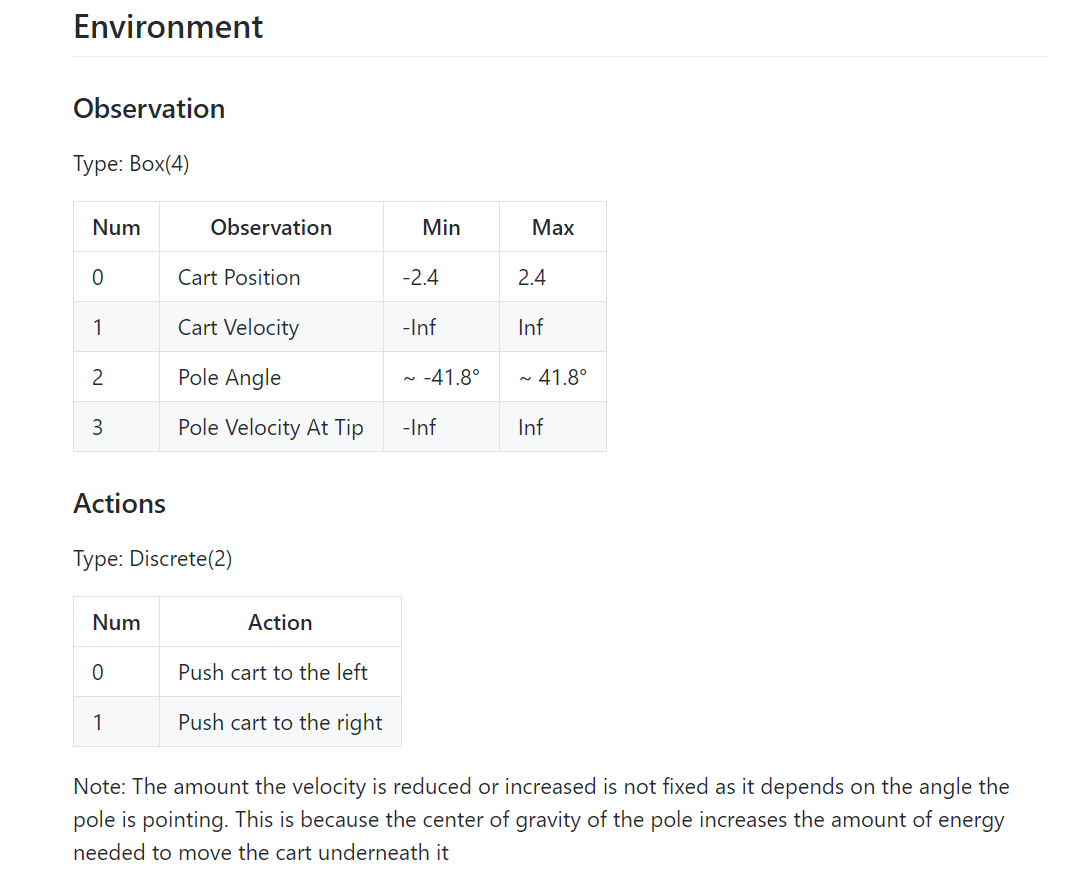
二、算法伪代码
图片主要来源于草帽B-O-Y的博客
NIPS 2013版本

Nature 2015:本篇笔记中使用的算法

三、代码介绍
3.1 代码组成
主要由两部分组成:dqn.py和run_CartPole.py
3.2 DQN实现(dqn.py)
主要包含(1)建cnn基本网络和Target目标网络(2)经验回放池数据存储(3)e-greedy行为选择(4)cnn神经网络训练等四部分
3.2.1 程序框架
主要包含以下几个函数
1 | import numpy as np |
3.2.2 初始化
1 | def __init__(self, |
3.2.3 创建Q网络和目标网络
Q网络和Target Q网络最大的不同在于Q网络的输入是$s$,而Target Q网络的输入是$s’$,其他的网络结构和初始化参数全部相同,Q网络的输出用self.q_eval表示,Target Q网络的输出用self.q_next表示。中间层设置为20
1 | def build_net(self): |
3.2.4 经验回放池的数据存储
这里的存储方式和莫烦的存储方式不太一样,当数量小于回放池的大小时,直接添加;若回放池已经存满,则删除掉最开始的第一个数据,在进行添加。
我看的网上的很多代码中都用了one_hot_action来表示行为,也不太清楚其功能,我这里没有用
1 | def store_transition(self,s,a,r,s_,done): |
3.2.5 e-greedy行为选择
以一定几率选择行为,随训练的进行,逐渐减小随机的可能性,选择最大的值
由于是采用的epsilon增加的方式,因此,当小于epsilon时,从Q网络中进行选取,否则,随机选取
这里添加了一个
.reshape(-1,self.s_dim),是因为在创建网络时,s_dim的维度已经用占位符更改,而这里接收到的state是直接从env环境中获取的,没有进行任何更改,如果不添加reshape,则会报维度不匹配的错误。
1 | def choose_action(self,state): |
3.2.6 训练cnn网络
首先,检查Target网络是否需要更新,若达到相应的步数了,则更新;
其次,在从回放池中获取数据时,要进行一下判断,判断当前的回放池数据n是否已经超多mini-batch,若没有,则直接随机采取n个数据,反之,则用mini-batch进行随机采样;
最后,通过mini-batch求期望获取Q值和Target Q值,并根据这两个值求Loss,并进行优化
1 | def learn(self): |
3.2.7 目标网络参数更新
1 | def train_target(self): |
3.3 主函数(run_CartPole.py)
1 | #!/usr/bin/env python |
3.4 全部代码
直接查看所有代码
四、结果显示
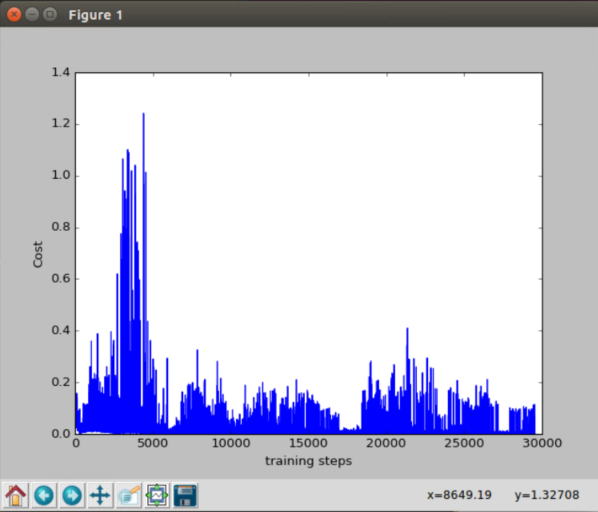
100个episode(某一次)的cost
100个episode(另一次)的cost和reward
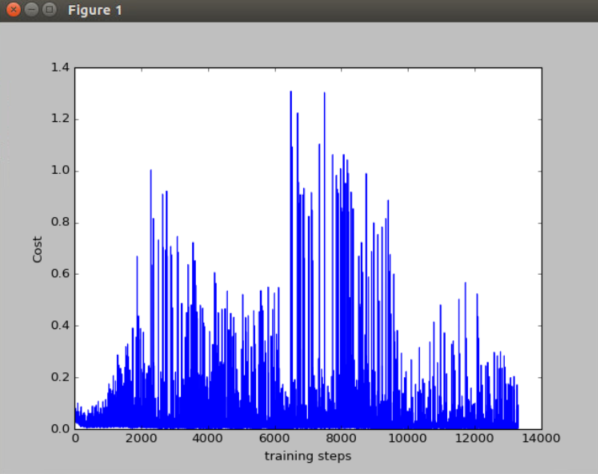
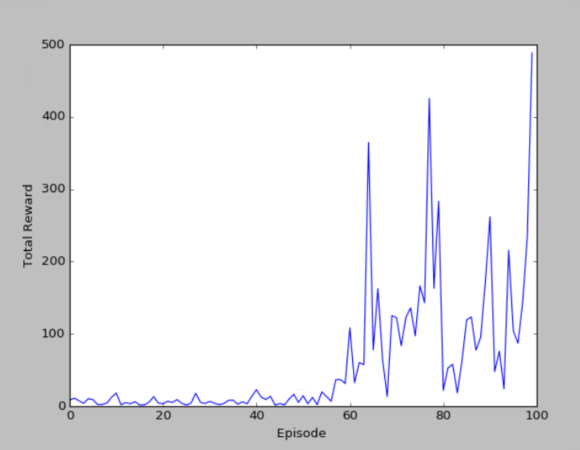
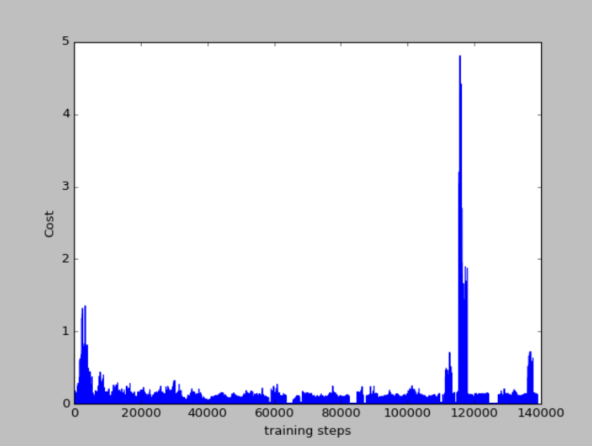
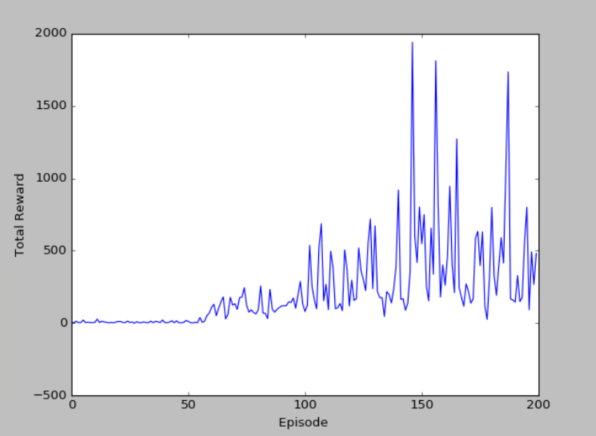
200个episode(另一次)的cost和reward
五、MountainCar例子
5.1 MountainCar问题说明
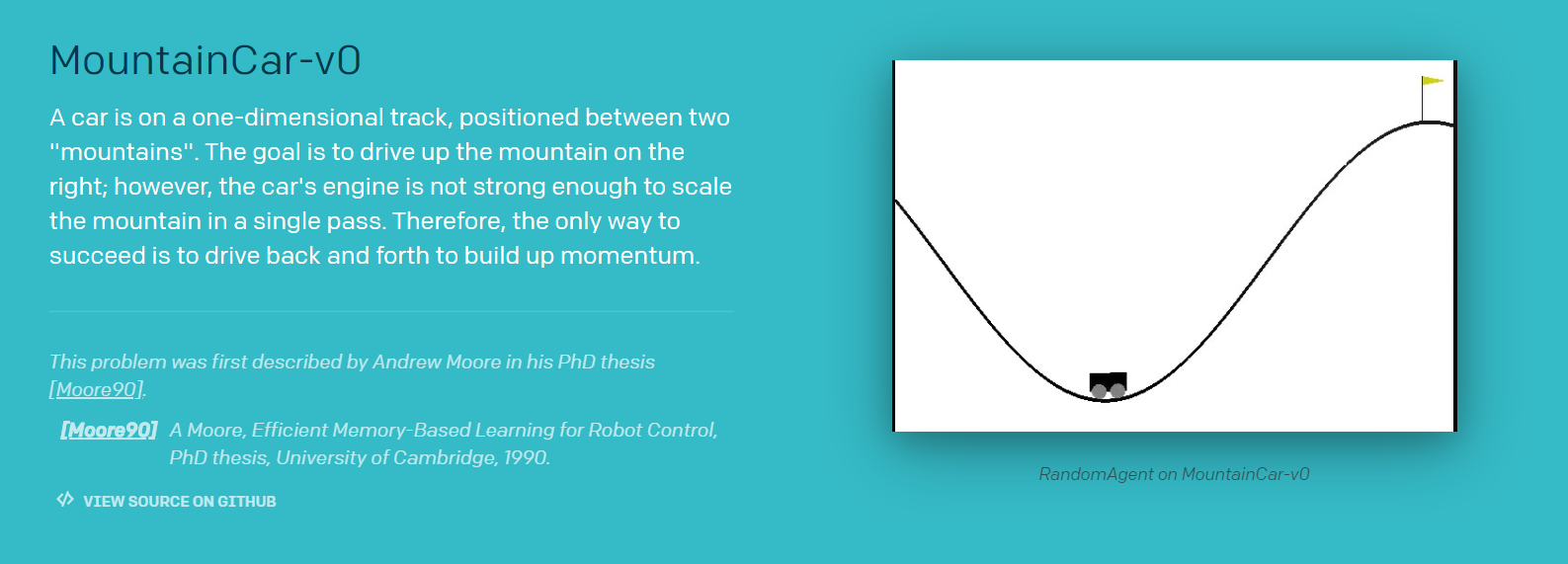
汽车位于一条轨道上,位于两个“山脉”之间。目标是在右边开山;然而,汽车的发动机强度不足以在一次通过中攀登山峰。因此,成功的唯一途径是来回驾驶以增强动力。
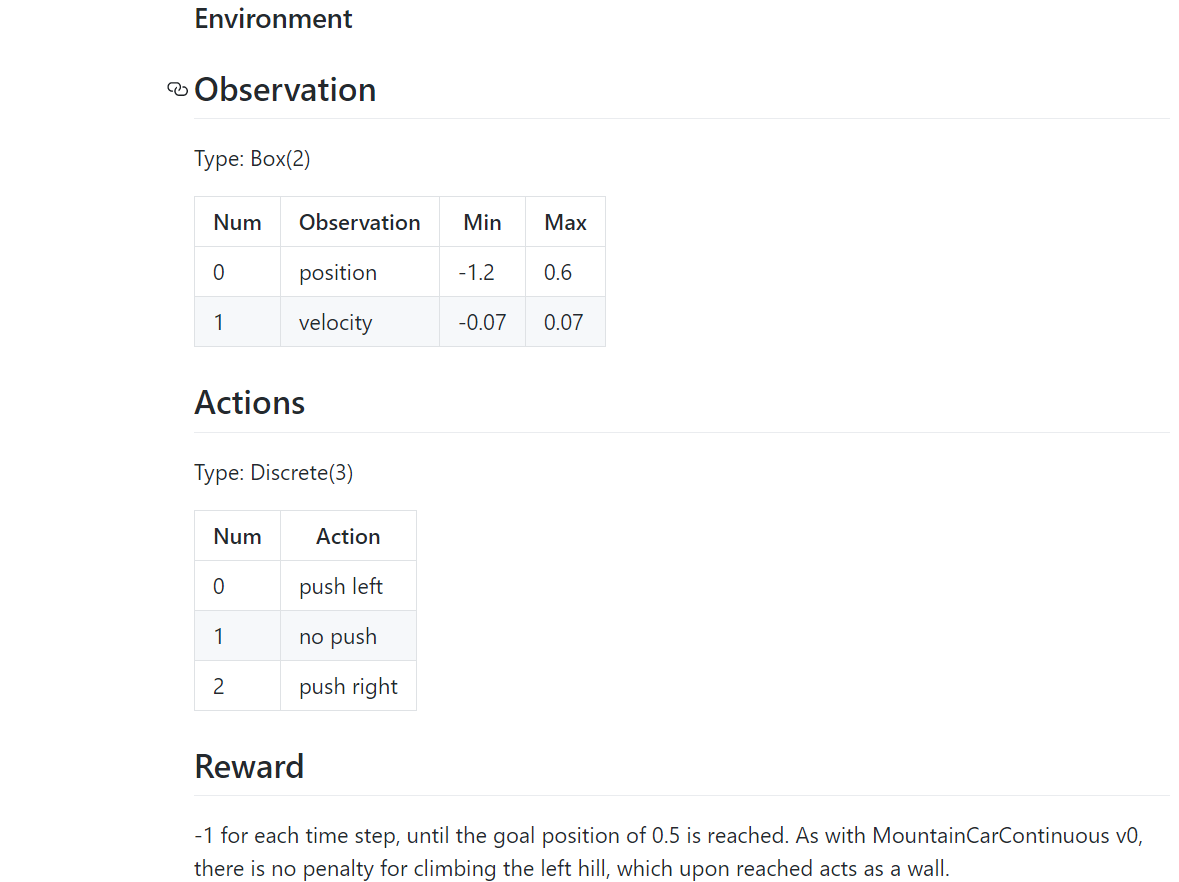
5.2 代码部分
dqn的代码部分不变,变化的知识主函数的代码,和run_CartPole.py的代码很类似,但有点小区别
下面说下run_MountainCar.py和run_CartPole.py的不同之处
(1)第一处不同(注释的为CartPole,没注释的为MountainCar)
首先,环境不同,因此状态维度和行为维度不相同,这个很正常。但是这里的学习率、目标网络更新步数、回放池大小、探索的增长速度值全部不相同。
1 | # RL = DQN(s_dim = env.observation_space.shape[0], |
(2)第二处不同(奖励不同)
MountainCar的奖励设置为position,这里加减是为了限定在[0,1]范围内。和前面一样,不同的环境奖励也不相同,这个奖励一般也还好设置。
1 | r = abs(position - (-0.5)) # r in [0,1] |
5.3 结果显示
我这里的cost的显示图和莫烦的cost的显示图不太一样,但其实在DRL算法中,看中的是累计奖励,即第二幅图和第四幅图。可以看出,累计奖励也是在慢慢的平缓,因为训练到后面,已经知道如何到达目标点,会比较快速的到达,而不用左右来回摇摆,因此是一个下降趋势。
10个episode
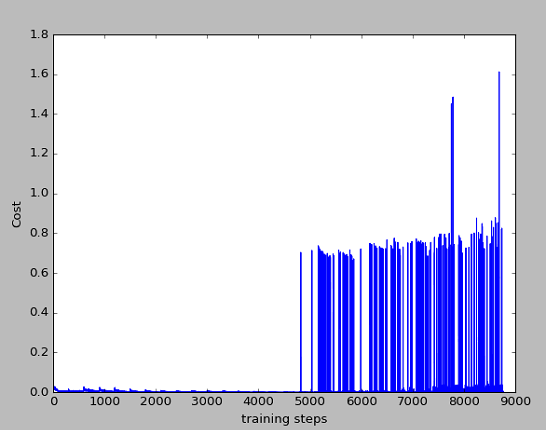
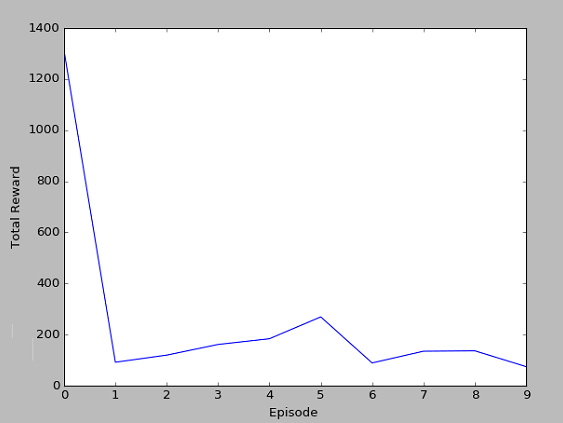
20个episode
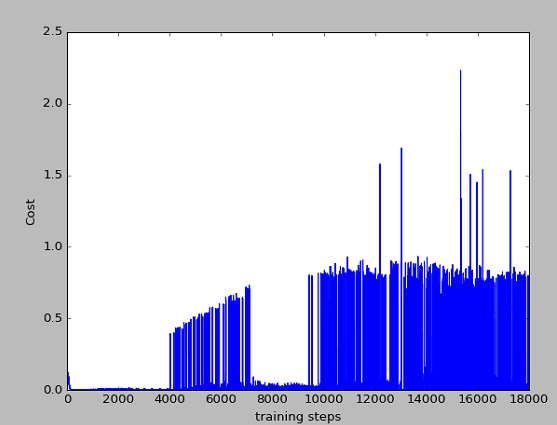
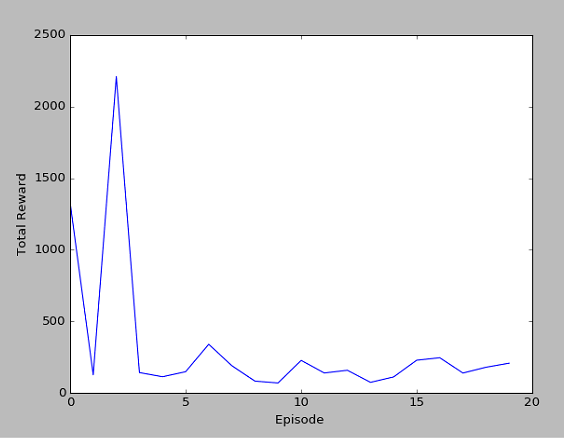
总结
到后面的时候,cost下降的还是较为明显,但仍然有波动,这可能是随机选择行为导致的结果,从模型中也可以看出有时候不太稳定,因此该算法还需要改进。在实际中,要看重累计奖励而不是损失函数。
从上面的两个不同例子中可以看出,不同的环境,在主函数中,学习率、回放池大小、探索的增长速度值、目标网络更新步数都会有所不同,甚至,在dqn.py中也会改变其网络结构,但是这些值又是如何试验找出一个比较合适的值的呢?这是一个问题