前言
理论部分,这里将不再强调,直接强调重点部分(理论部分请点击Double DQN)
经验证,DQN中使用max操作,会使得其Q值会出现过估计的情况,因此提出了DQN的改进算法之一:Double DQN;Double DQN就是将DQN中的目标Q值的动作与计算分离,来减缓过估计情况。
本文的代码,主要参考莫烦大神的代码,只做了少量的修改。
一、实验环境
总共测试了三种环境,其中CartPole和MountainCar的环境,在上一节已经介绍过,这一次,添加了一个Pendulum环境。
1.1 Pendulum环境简单介绍
目标说明:详细网址
倒立摆摆问题是对照文献中的经典问题。在这个版本的问题中,钟摆以随机位置开始,目标是将其向上摆动,使其保持直立。
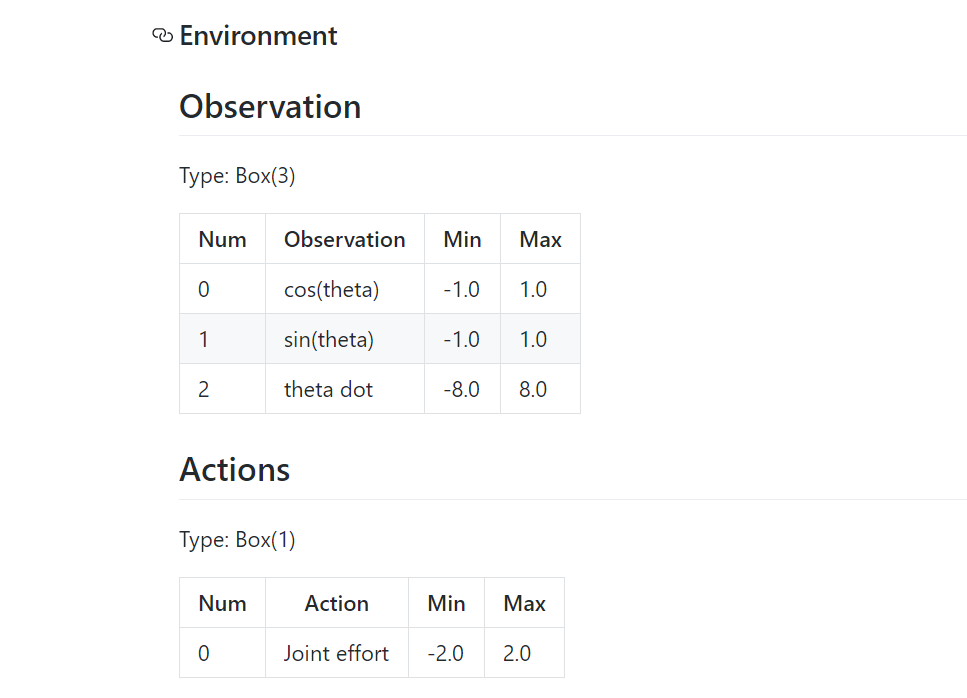
环境介绍:详细网址,pendulum源代码
二、Double DQN
在DQN中,其$Y_t^{DQN}$的计算公式为:
其中,$\theta_t^-$为$Target Q$的网络参数。
正是因为其max操作,使得其Q值可能比真实值要高,导致动作-值函数过估计。
而Double DQN中,则对$Y_t^{DQN}$进行了一个小小的改动,改动后如下:
使用Q网络的参数$\theta$来估计贪婪策略的价值,使用$TargetQ$网络的参数$\theta^-$来公平的评估该策略的价值
三、代码部分
Double DQN的代码相比于DQN,只改动了一处。直接查看所有代码
3.1 代码组成
所有代码里面,主要包含6个代码:
(1)ddqn.py和ddqn_truth.py
这两个代码几乎完全一致,不同的是,在ddqn.py中,只包含ddqn的算法;而在ddqn_truth.py中,同时包含了ddqn算法和dqn算法,并且添加了求真实Q-values的值
(2)run_CartPole.py
这个和上一节DQN里面的代码基本完全一致,较之前,多了一个测试环节,测试训练的效果,测试差不多能达到300分。并且主要用于展示损失函数图和累计奖励图
(3)run_MountainCar.py
这个就和上一节的完全一致了,除了调用的是DDQN外,就没有区别了
(4)run_CartPole_truth.py和run_Pendulum.py
这两个主函数里面代用的则是ddqn_truth.py函数,最终用于展示其DQN和Double DQN的过估计情况
3.2 网络-ddqn.py
主要用来显示损失函数图和累计奖励图
ddqn.py
1 | q_next = self.sess.run(self.q_next,feed_dict={self.s_:next_states}) |
dqn.py
1 | q_next = self.sess.run(self.q_next,feed_dict={self.s_:next_states}) |
Double DQN 和DQN的代码的主要差别如上,很明显:
首先,在Double DQN中,多了一个Q值:q_eval_next
1 | q_eval_next = self.sess.run(self.q_eval,feed_dict={self.s:next_states}) |
这一行对应了公式里面的:$Q(S_{t+1},a;\theta_t)$
值得注意的是,这里仍然用的是Q网络,但是状态为下一状态$S_{t+1}$
然后,在计算时首先求出$argmax$,
1 | max_action_next = np.argmax(q_eval_next,axis=1) |
这一行则对应了$\arg\maxa Q(S{t+1},a;\theta_t)$,这样就得到了行为$a$
最后则是计算$Y_t^{DQN}$
1 | q_target[k][actions[k]] = rewards[k] + self.gamma * q_next[k,max_action_next[k]] |
通过
1 | q_next[k,max_action_next[k]] |
则直接获取$Q’(s,a)$的值,而不再是用
1 | np.max(q_next[k]) |
获取$\max Q’(s,a)$,要注意这其中的区别
3.3 网络-ddqn_truth.py
把dqn和ddqn算法全部添加进来,并且计算真实Q-values值,用于展示dqn和ddqn与真实Q-values之间的差别的图形
(1)在init函数里面,主要多了double_q和sess的变量,其中double_q的变量是为了判断是否用ddqn,还是dqn。因为要展示两种算法与真实Q-values之间的差异,因此还需要接收主函数输入的sess
1 | def __init__(self,double_q = True,sess = None): |
(2)在e-greedy行为选择这里,添加了计算真实Q-values的代码,其真值通过
1 | self.running_q = self.running_q * 0.99 + 0.01 * np.max(actions_value) |
来实现(为什么?还没有去思考)
1 | def choose_action(self,state): |
(3)在learn函数里面,通过self.double_q来判断是否用double dqn算法
1 | def learn(self): |
3.4 主函数-run_CartPole.py
和第一节有所不同的是,在训练过程中添加了测试的部分
1 | total_steps = 0 |
3.5 主函数-run_Pendulum.py
显示dqn和ddqn算法相比于真实Q-values差异的图像
需要说一下的是,因为需要计算dqn和ddqn的值,并显示,因此在这里需要创建两个RL,通过double_q来判断使用何种算法。
1 | #!/usr/bin/env python |
另外,这里的行为维度a_dim为11,是将原本的连续动作离散化为11个动作,至于为什么离散化为11个动作?
可能是因为在源码里面,将行为限定在了[-8,2]里面,因此输入的有11维
1 | self.max_speed=8 |
而后面又将获取到的行为做下面操作
1 | f_action = (a-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # convert to [-2 ~ 2] |
是因为在环境介绍部分说明了行为的界限范围[-2,2],所以才做的该操作
至于$r = r /10$,将奖励限定在(-1,0)的操作还没太看懂,我觉得应该是除以20才对,在介绍部分说明了奖励的取值范围为[-16,0]

最后,则显示了两个算法与真实Q-values的差异图像
四、结果显示
DDQN算法
(1)run_CartPole.py
100个episode的损失函数如和累计奖励图
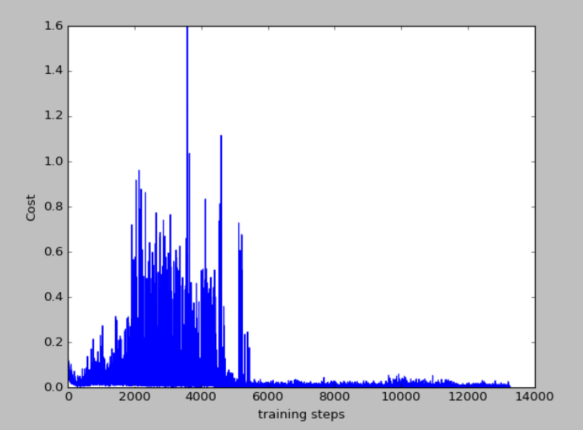
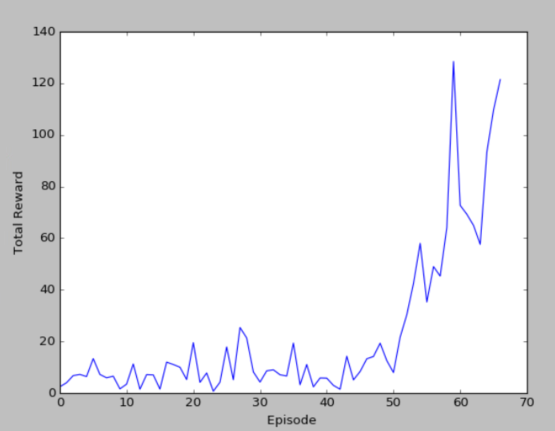
(2)run_CartPole_truth.py
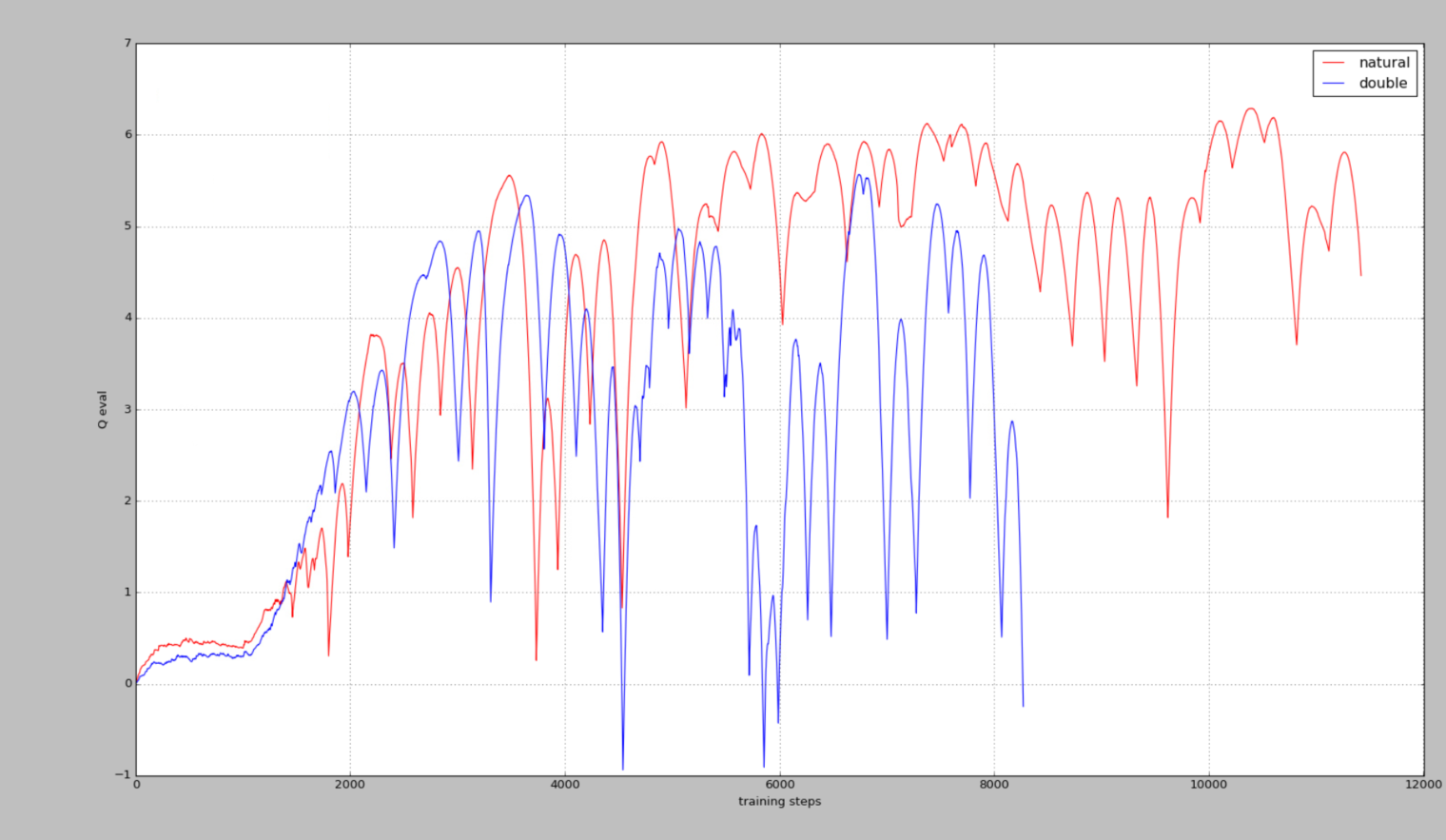
100个episode训练过车中的动作-值函数的近似
可以看出Double DQN比 nature DQN的值还是要低一些的,即能缓解其过度估计情况,不知道真实值是多少,只是输出来看看效果
(3)run_MountainCar.py
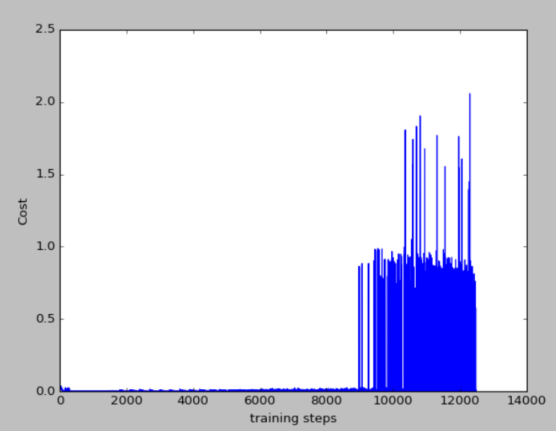
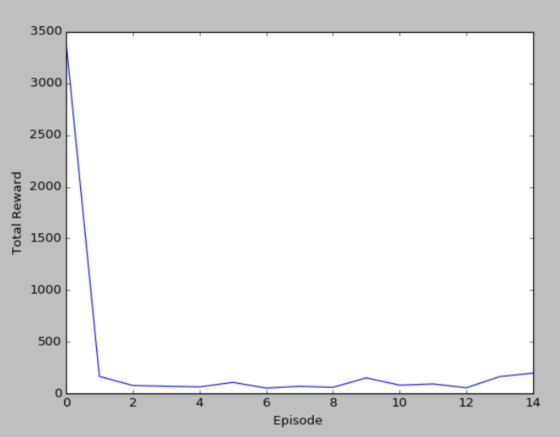
15个episode的损失函数图和累计奖励图
(4)run_Pendulum.py
这个是用莫烦的代码跑的
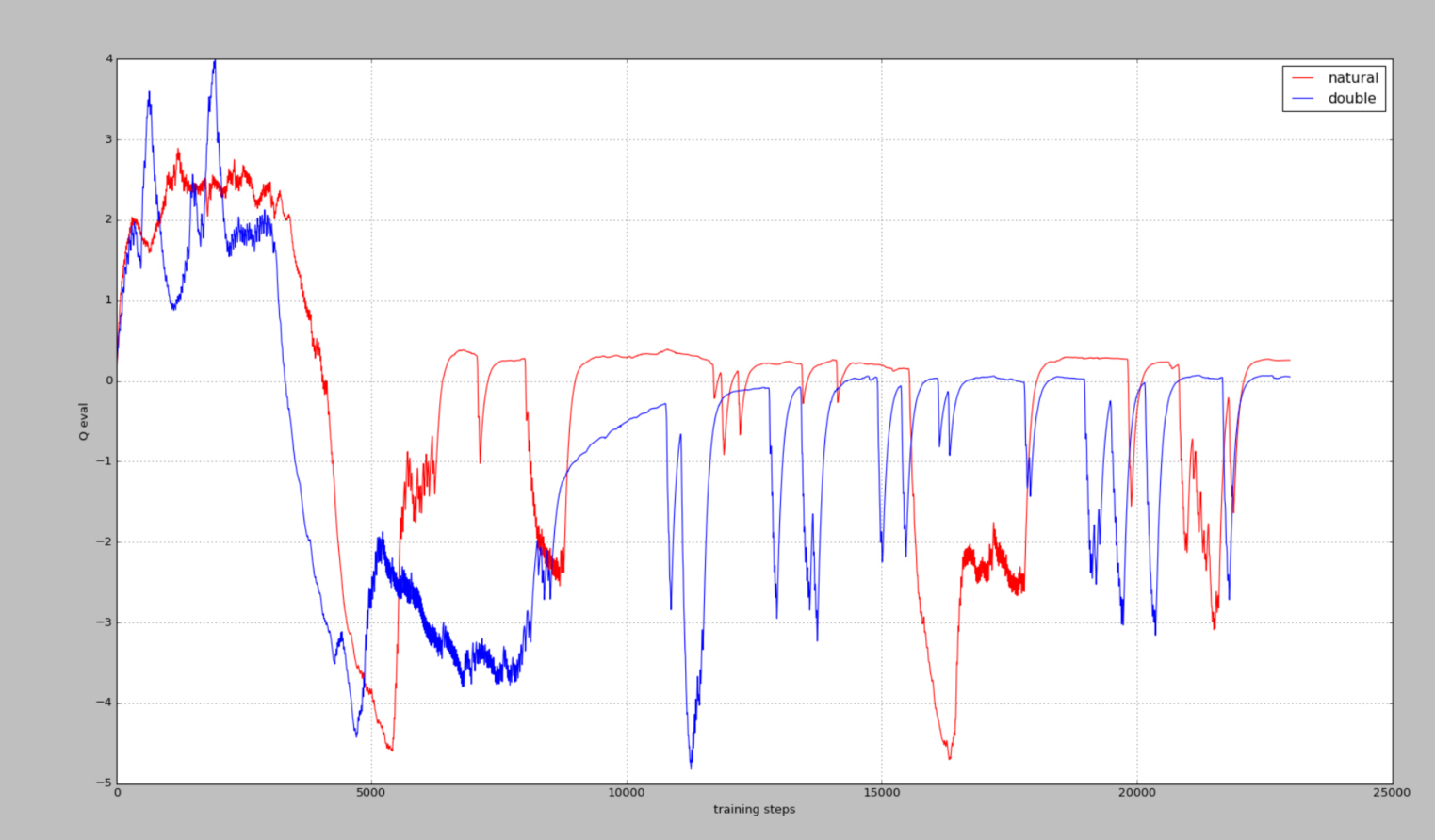
而下图则是我根据莫烦的代码修改后,测试的,图像当然是差不多的,至少证明了我改写过后的代码是没有问题的(虽然只改动了一点点,但是改为自己习惯的就好)
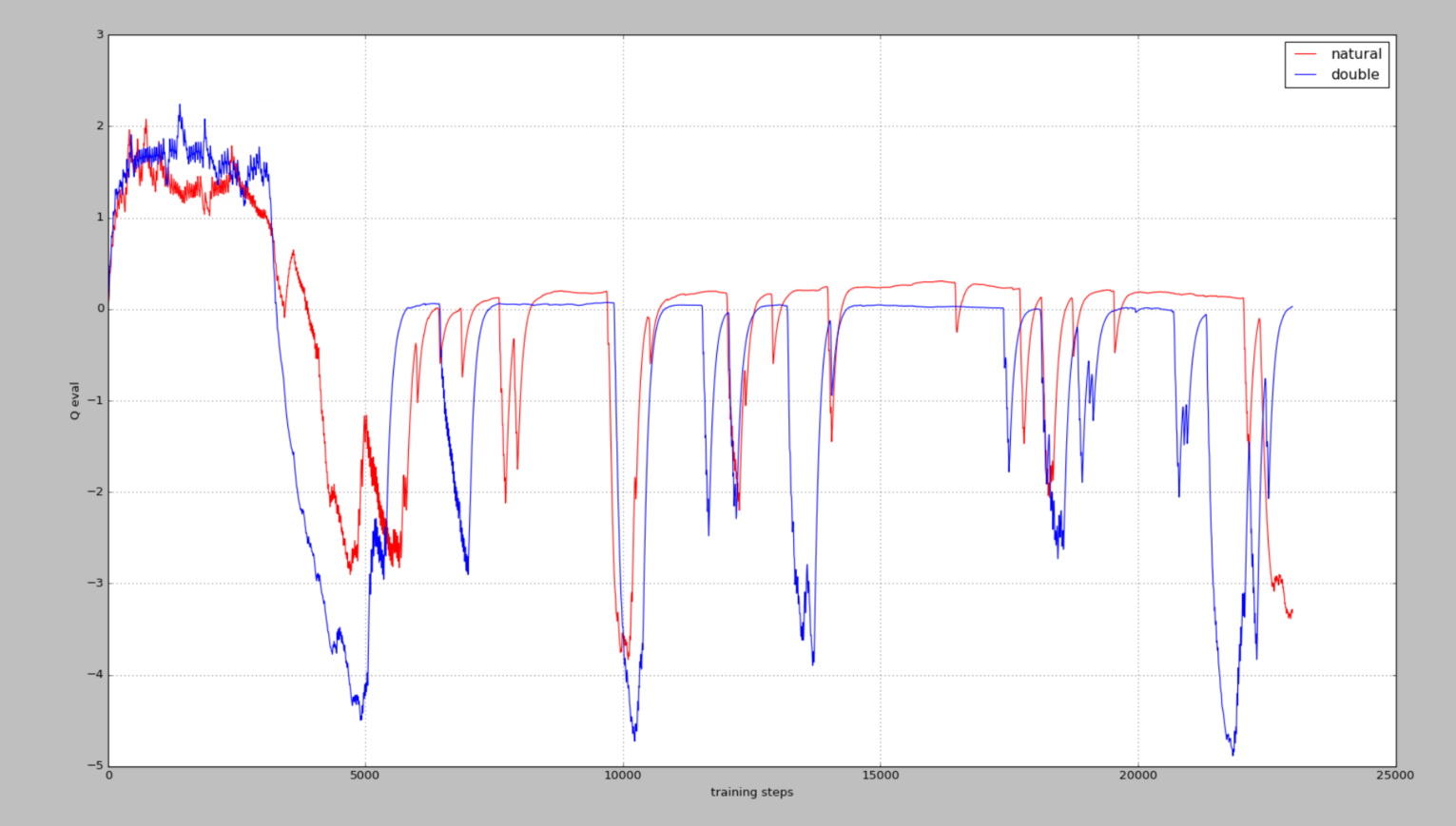
从这个图中则可以看出,我们的真实Q-values值是0,而Nature DQN在预估的过程中,存在不少高估的情况,改用Double DQN,则会好很多
总结
通过这个实验对Double DQN有了更加深刻的了解,并且对DQN的高估也有了一个较直观的理解,但是对里面的一些参数是如何确定的,这点还是有点疑惑,目前还是主要以理解算法为主