前言
Dueling DQN 相比较于之前的Double DQN(目标Q值方面的优化)、Prioritized Experience Replay(经验回放池的优化),这次注重的是神经网络的优化,即将最后的Q网络分为V网络和A网络。
其中,V网络仅仅与状态S有关,与具体要采用的动作A无关,通常称为状态价值函数;
A网络同时与状态S和动作A有关,通常称为动作优势函数。
其理论部分,点击DRL论文阅读(四)
本文的代码主要参考莫烦的代码来修改的。
一、实验环境
使用Pendulum来作为实验环境
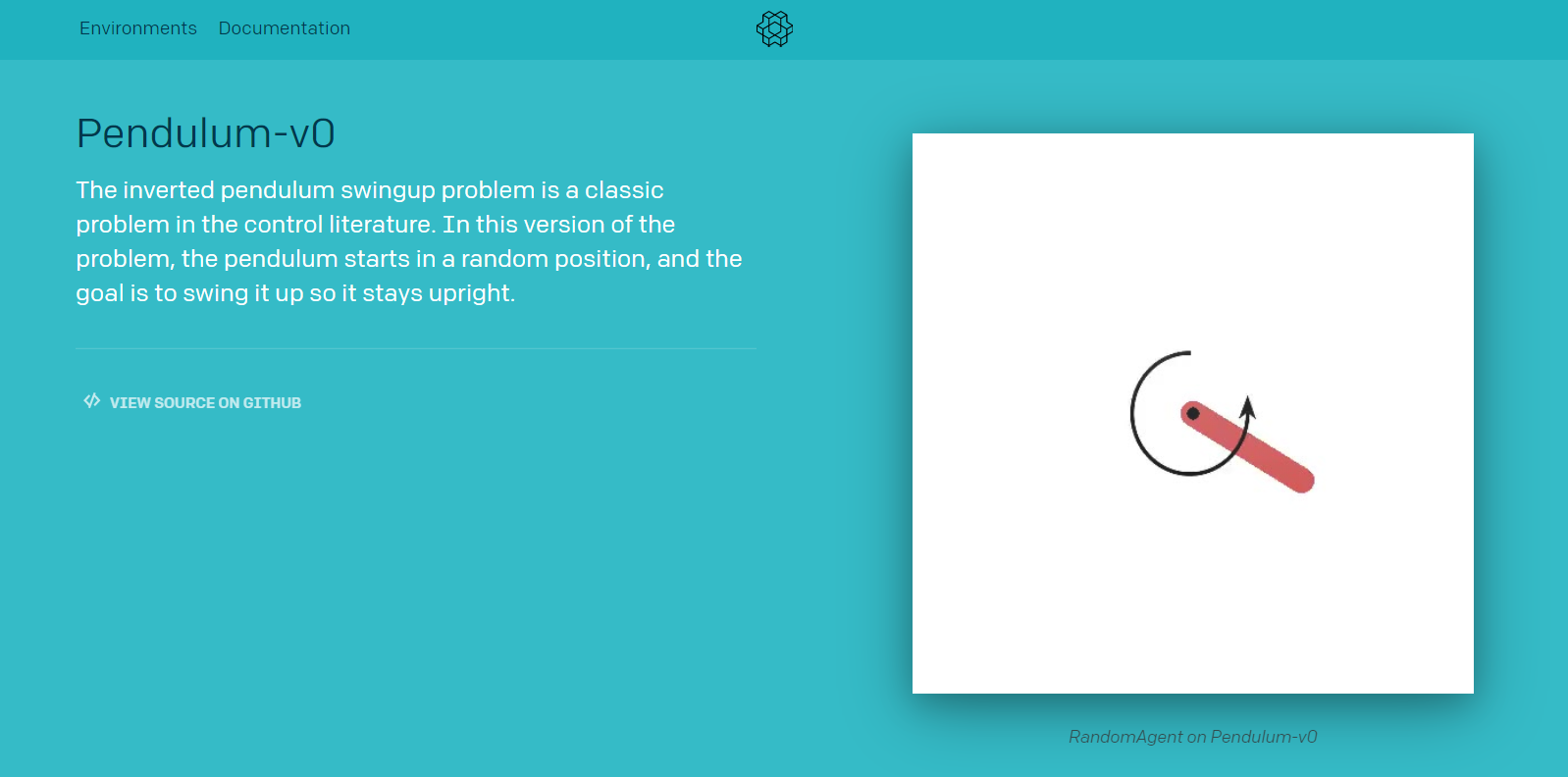
这个实验环境的动作空间是连续的,其范围为[-2,2]。在前面的Double DQN实验中,我们将连续动作空间离散化为11个动作。
在本节的实验中,将分别离散化为5、15、25、35个行为空间来看其效果。
二、Dueling DQN
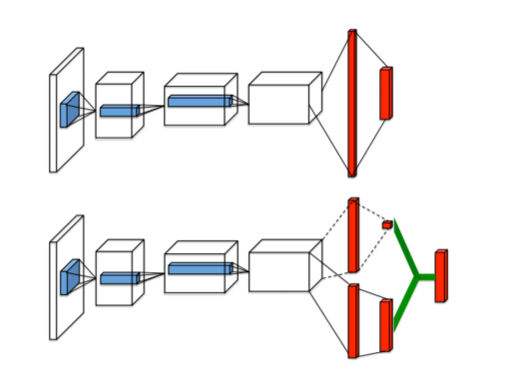
传统的Nature DQN的输出最后是卷积层先经过全连接层,然后在输出对应于每个动作行为a的值。
而现在的Dueling DQN则是将最后一个卷积层的输出分为两部分,分别是V网络和A网络,如下图下方的分支中,上面的为V网络,下面的为A网络。
其中
- V(s):V(s)表示状态本身的好坏,一般为一个值(标量)。
- A(s,a):A(s,a)表示当前状态下采取的行为的好坏,一般为n个值,因此A网络决定了策略
Dueling DQN的Q网络计算公式如下:
其中,$\theta$为卷积层参数,$\beta$为V网络全连接层参数,$\alpha$为A网络全连接层参数
三、代码部分
Dueling DQN相比于Nature网络,只在最后的网络结构部分改变了一点点,其他的都没有任何变化
若想看完整代码,直接查看所有代码
3.1 代码组成
本节的代码主要包含两个部分:dueling_dqn.py和run_Pendulum.py
3.2 网络-dueling_dqn.py
只在网络结构部分发生了变化
1 | class DueilingDQN(object): |
在V网络中,因为其输出是一个标量值,因此维度这里为[20,1]
1 | w2 = tf.get_variable('w2',[20,1],initializer=w_initializer,collections=c_names) |
而A网络的输出,对应的每个a的值,因此维度为[20,self.a_dim]
1 | w2 = tf.get_variable('w2',[20,self.a_dim],initializer=w_initializer,collections=c_names) |
最后,V和A网络合并,成为Q网络
1 | self.q_eval = self.V + (self.A - tf.reduce_mean(self.A,axis=1,keep_dims=True)) |
3.3 主函数-run_Pendulum.py
1 | env = gym.make('Pendulum-v0') |
四、结果显示
5个actions
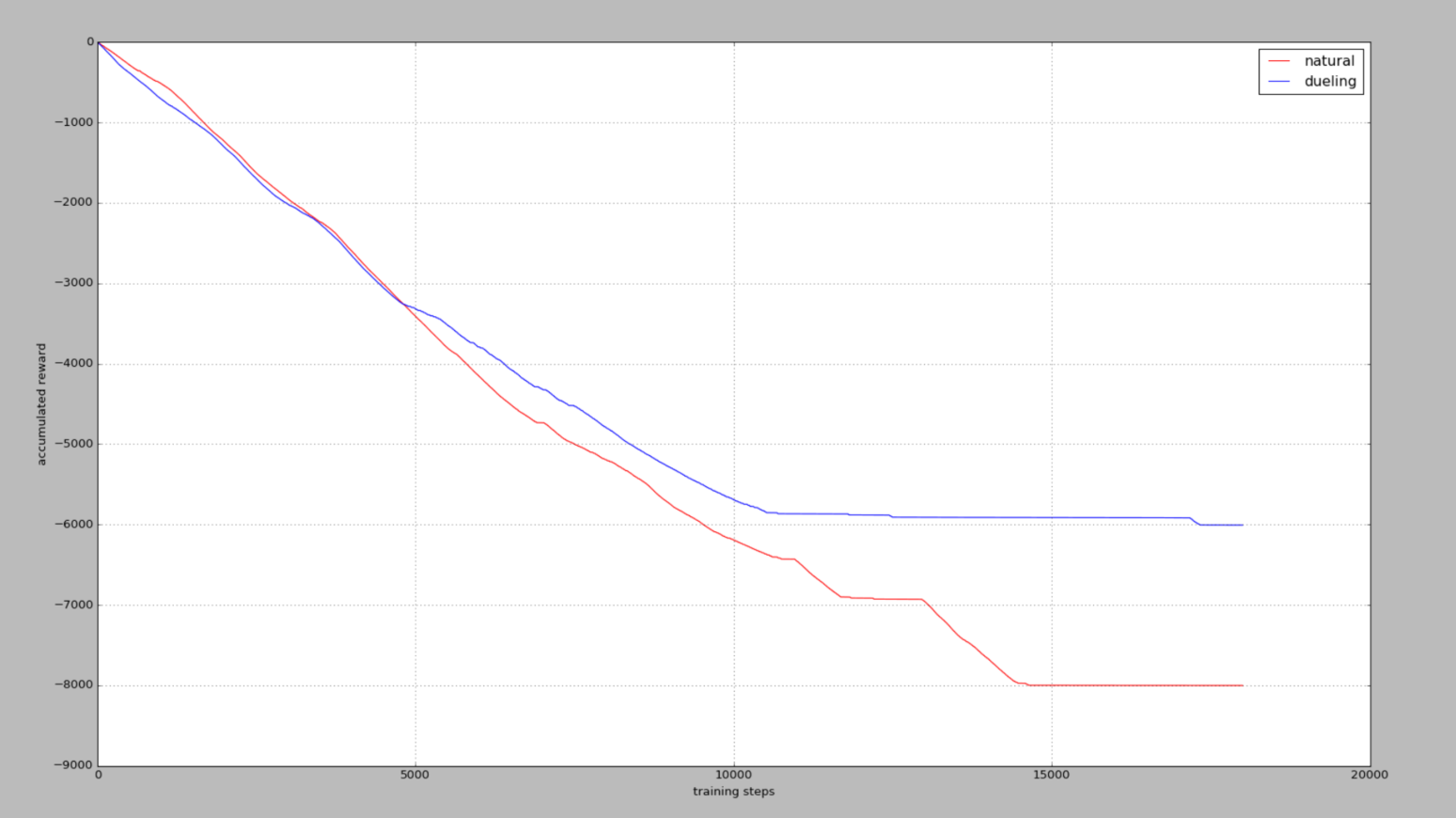
15个actions
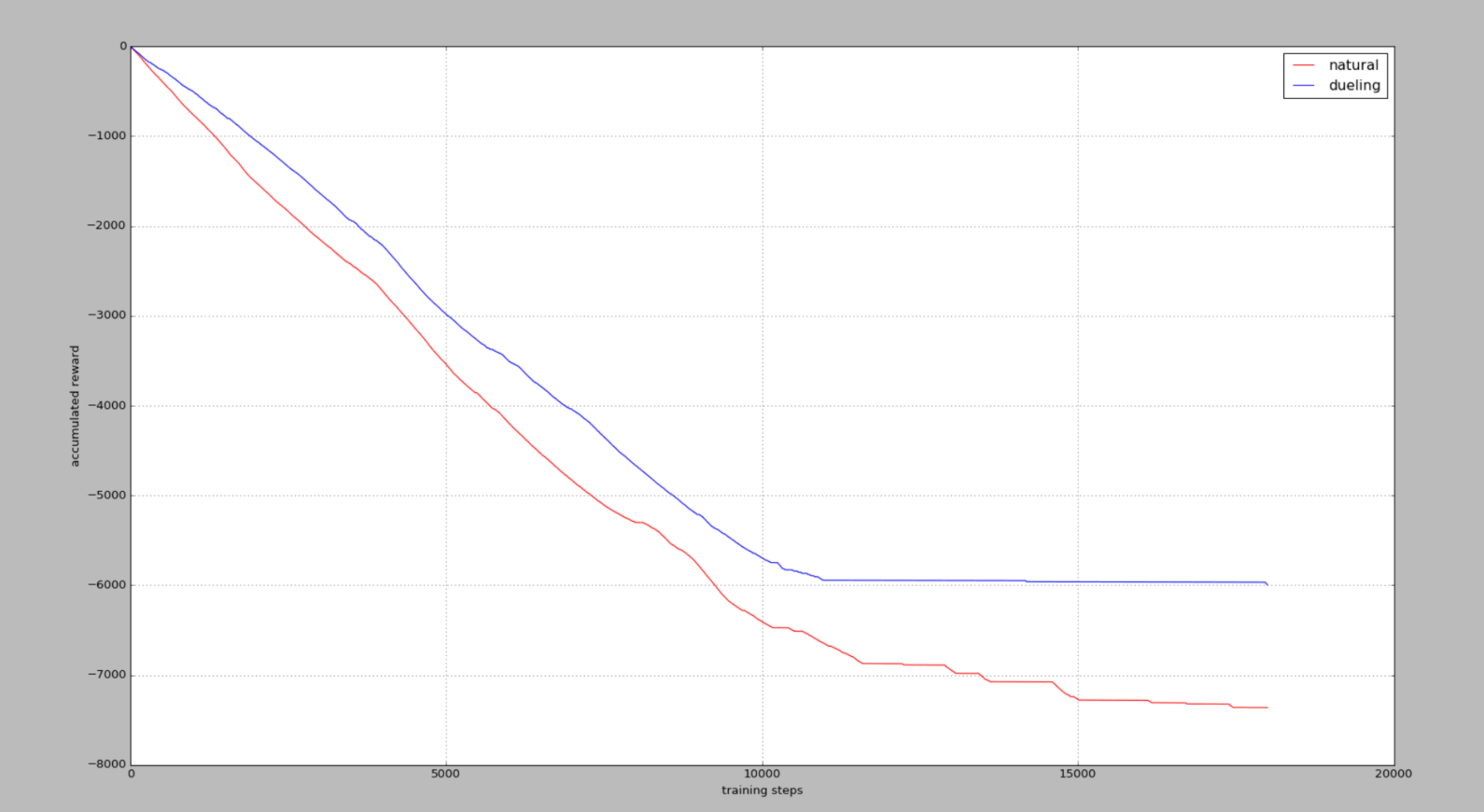
25个actions
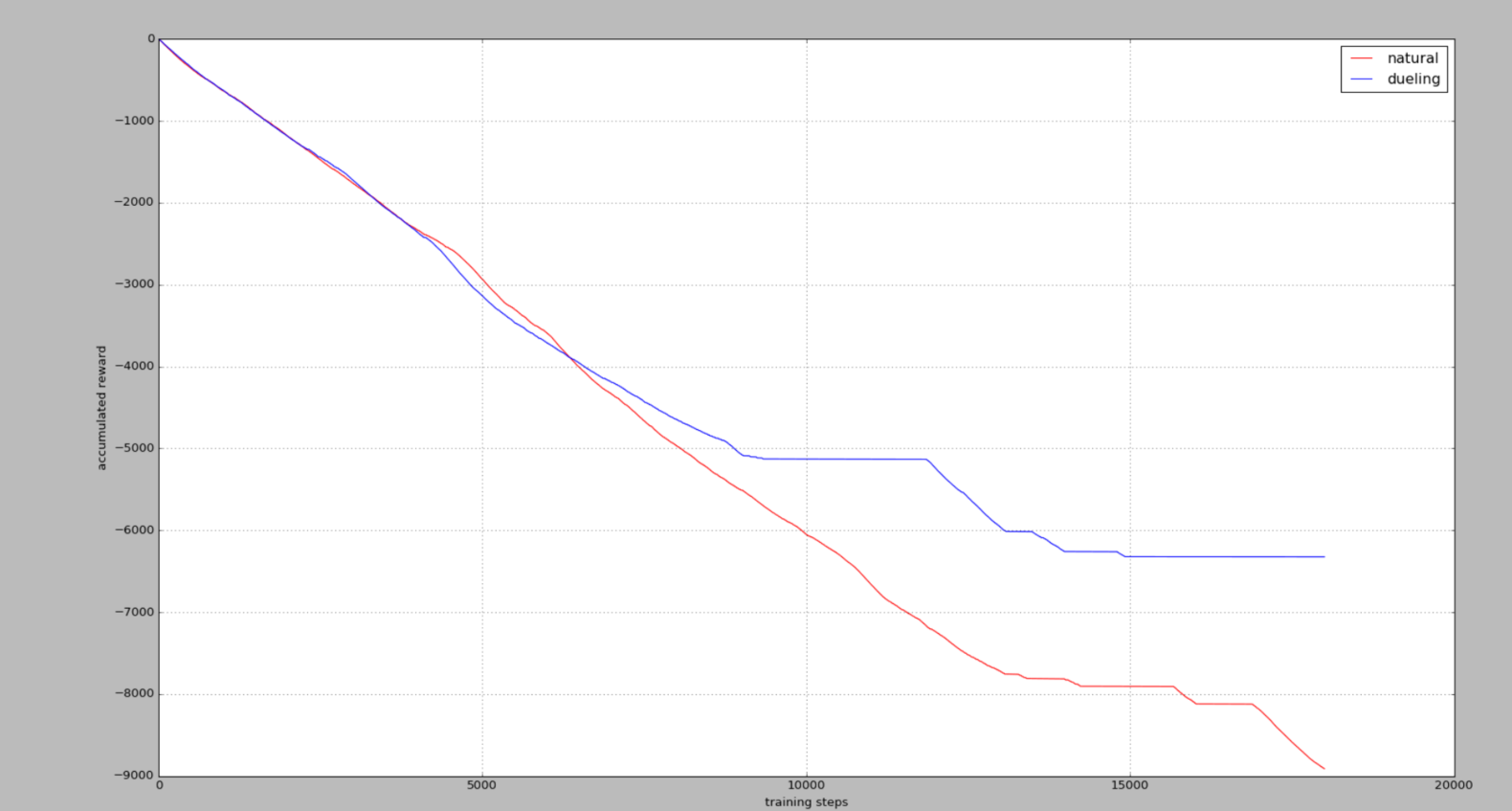
35个actions
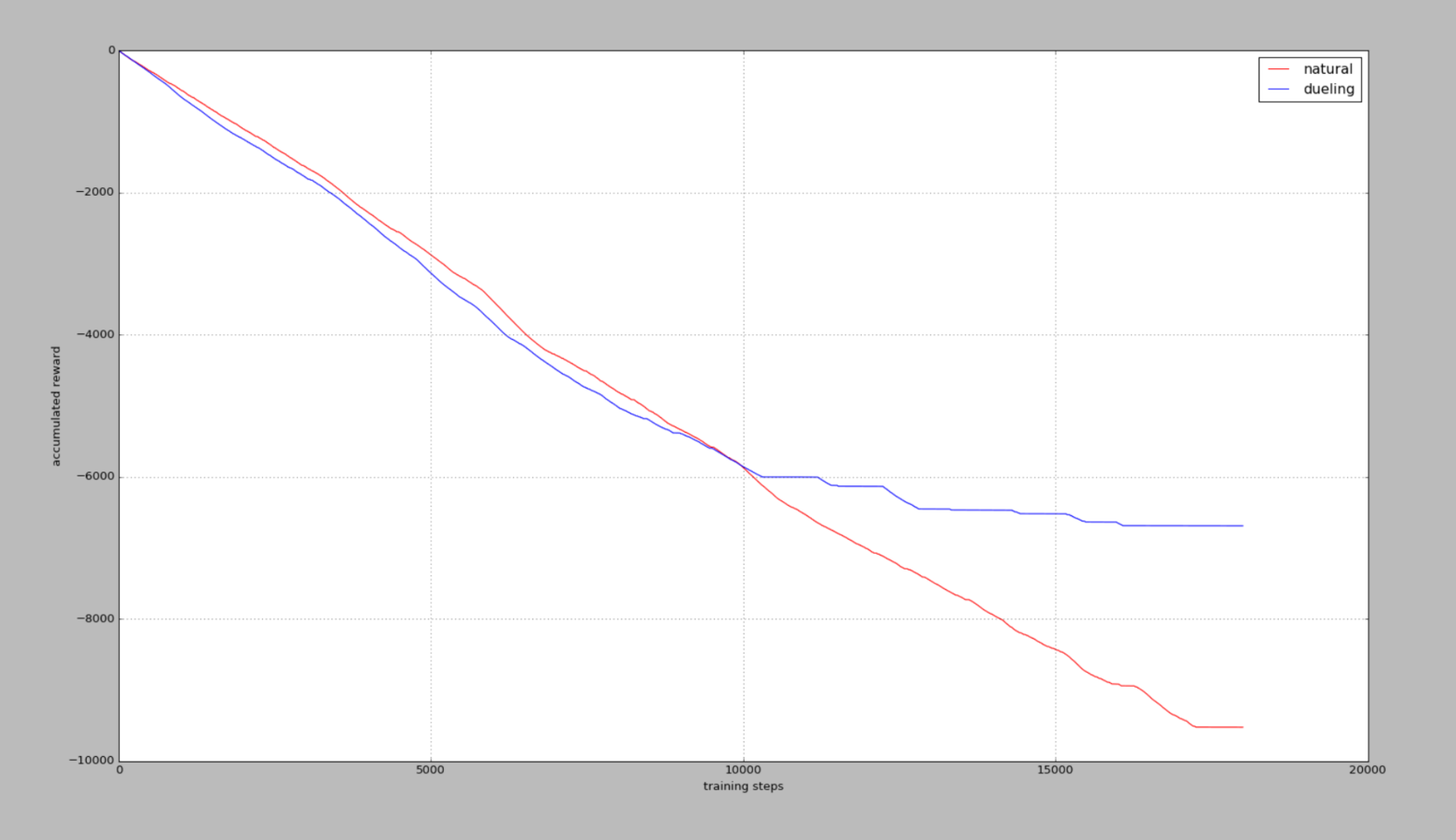
累积奖励reward,在杆子立起来的时候奖励为0,其他时候都是负值,所以当累积奖励没有在降低时2,说明杆子已经被成功立很久了。
我们发现当可用动作越高,学习难度就越大,不过Dueling DQN还是回比Nature DQN学习得更快,收敛效果更好。
总结
至此,DQN即DQN的三个优化方面的代码已经全部简单测试完毕,并且也差不多了解了其代码,对原理将会更加理解,其中Prioritized Experience Replay的代码部分最为复杂,Double DQN只在最后计算Q值的部分改动了一点点,Dueling DQN在网络结构部分改变了一点点。
后面,将会开始Policy Gradient的代码学习。