前言
Policy Gradient是RL里面基于Policy-Based的方法,与前面的DQN的基于Value-Based的方法不同。其理论部分,查看DRL论文阅读(五)
本篇代码是基于莫烦的代码,然后进行了少量的修改,实践中使用的是离散行为空间的softmax策略函数,而不是连续行为空间的高斯策略函数
一、实验环境
使用CartPole和MountainCar作为实验环境,这里将不再对环境进行说明
二、Policy Gradient
算法伪代码:采用的是蒙特卡洛策略梯度reinforce算法(不带基数)
它是一个基于整条回合数据的更新,即在训练之前,要先收集整个episode的(s,a,r),然后在进行参数更新
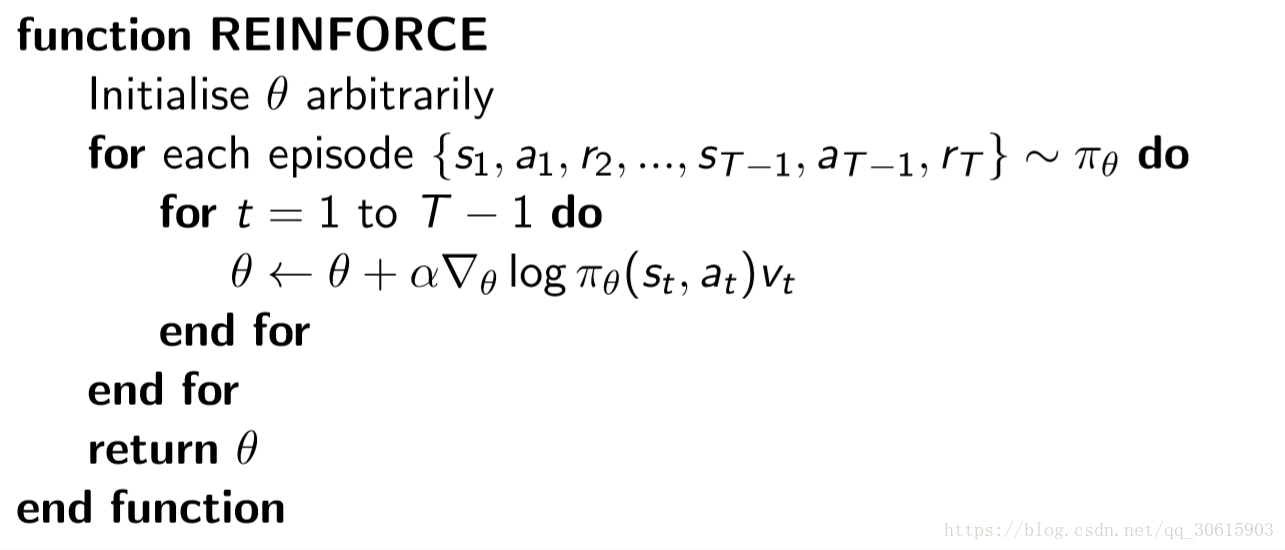
$\nabla\theta log \pi\theta(s,a)v$ 表示在状态$s$对所选动作 $a$ 的吃惊度,如果 $\pi\theta(s,a)$ 概率越小,则反向的 $log\pi \theta(s,a)$ (即 $-log\pi \theta(s,a)$ )越大,如果在 $\pi\theta(s,a)$ 很小的情况下,拿到了一个大的 $R$ ,也就是大的 $V$ ,则 $-\nabla\theta log \pi\theta(s,a)v$ 就更大,表示更吃惊(我选了一个不常选的动作,结果发现它得到了一个好的reward,那我就得对我这次的参数进行一个大幅度的修改)。这也就是吃惊度的物理意义。
策略梯度公式
策略函数:
softmax策略函数
其中,$\phi(s,a)$表示状态-动作对的L维特征向量
高斯策略函数
三、代码部分
直接查看完整代码
3.1 代码组成
代码主要由三部分组成:policy_gradient.py、run_CartPole.py、run_MountainCar.py
3.2 网络-policy_gradient.py
1 | #!/usr/bin/env python |
部分语句解释:
(1)*.shape[1]和ravel函数
这里取prob_weights.shape[1]表示获取prob_weights的列个数,.shape[0]则表示行个数,即行为的维度
ravel函数表示扁平化,即拉成一个维度,ravel函数详情
1 | action = np.random.choice(range(prob_weights.shape[1]),p=prob_weights.ravel()) |
(2)zeros_like函数
返回与指定数组具有相同形状和数据类型的数组,并且数组中的值都为0。函数详情
1 | discounted_ep_rs = np.zeros_like(self.ep_rs) |
(3)reversed函数
反转,PG算法中是前向,不是后向,因此需要反转。函数详情
1 | for t in reversed(range(0,len(self.ep_rs))): |
(4)np.std函数
计算矩阵标准差,函数详情
1 | discounted_ep_rs /= np.std(discounted_ep_rs) |
(5)np.vstack函数
按照垂直方向堆叠数组,函数详情
1 | self.s:np.vstack(self.ep_obs), |
(6)tf.nn.sparse_softmax_cross_entropy_with_logits函数
这个地方没怎么搞懂,函数详情
1 | neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act,labels=self.tf_acts) |
但若是换成这一种表达方式的话就是指:
self.all_act_prob表示所有的行为对应的概率;
tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions)这样就能知道我采取的是哪一个行为,而用one_hot则是为了用矩阵相乘,因为前面的是矩阵,one_hot只有被采取的行为为1,其他的为0。
添加负号是因为tf没有最大化,只有最小化,而我们想要实现log的最大化,即最小化-log
1 | neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1) |
注:疑惑的地方,没弄懂
(1)这里的这两个输入,为什么是[None,],后面为什么是空的?
1 | self.tf_acts = tf.placeholder(tf.int32,[None,],name="actions_num") |
(2)计算损失函数
这里的损失函数,干嘛要求均值呢?即用tf.reduce_mean?
softmax策略函数体现在哪里,只是在前面直接用来求最后的输出层就可以了吗?这样就是用的softmax策略函数?那么前面关于softmax策略函数的梯度公式给出是干啥的呢?$\nabla\theta log\pi\theta(s,a) = \phi(s,a) - E_{\pi\theta}[\phi(s,\cdot)]$
1 | with tf.variable_scope('loss'): |
这里用的损失函数的优化器,选用的是Adam,而不是前面DQN相关的RMSP
3.3 主函数-run_CartPole.py
1 | #!/usr/bin/env python |
3.4 主函数-run_MountainCar.py
1 | #!/usr/bin/env python |
四、界面显示
参考莫烦讲解
run_CartPole.py
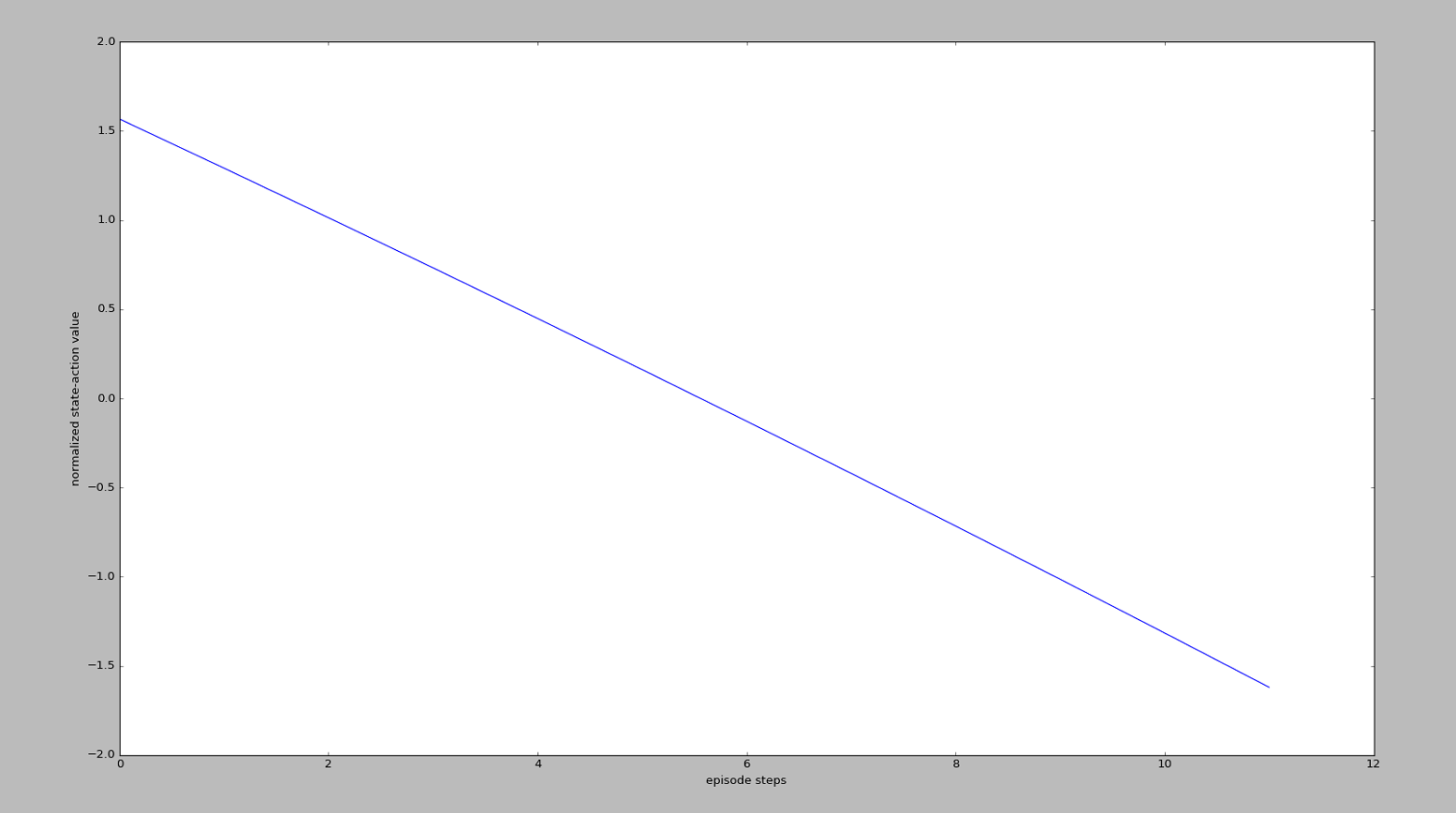
可以看出,左边的$v_t$有较高的值,右边的$v_t$有较低的值,也就说通过$v_t$再说明:
“请重视我这回合刚开始时的一系列动作,因为前面一段时间杆子还没有掉下来,而且请惩罚我之后的一系列动作,因为后面的动作让杆子掉下来了”或者是
“我每次都想让这个动作在下一次增加被选的可能性($\nabla\theta log \pi\theta(s,a)$),但是增加可能性的这种做法是好还是坏呢?这就要由$v_t$告诉我了,所有后一段时间的增加可能性做法并没有被提倡,而前段时间的增加可能性做法是被提倡的。”
这样,$v_t$就能通过
1 | loss = tf.reduce_mean(neg_log_prob * self.tf_vt) |
诱导gradient descent朝着正确的方向发展了。
run_MountainCar.py
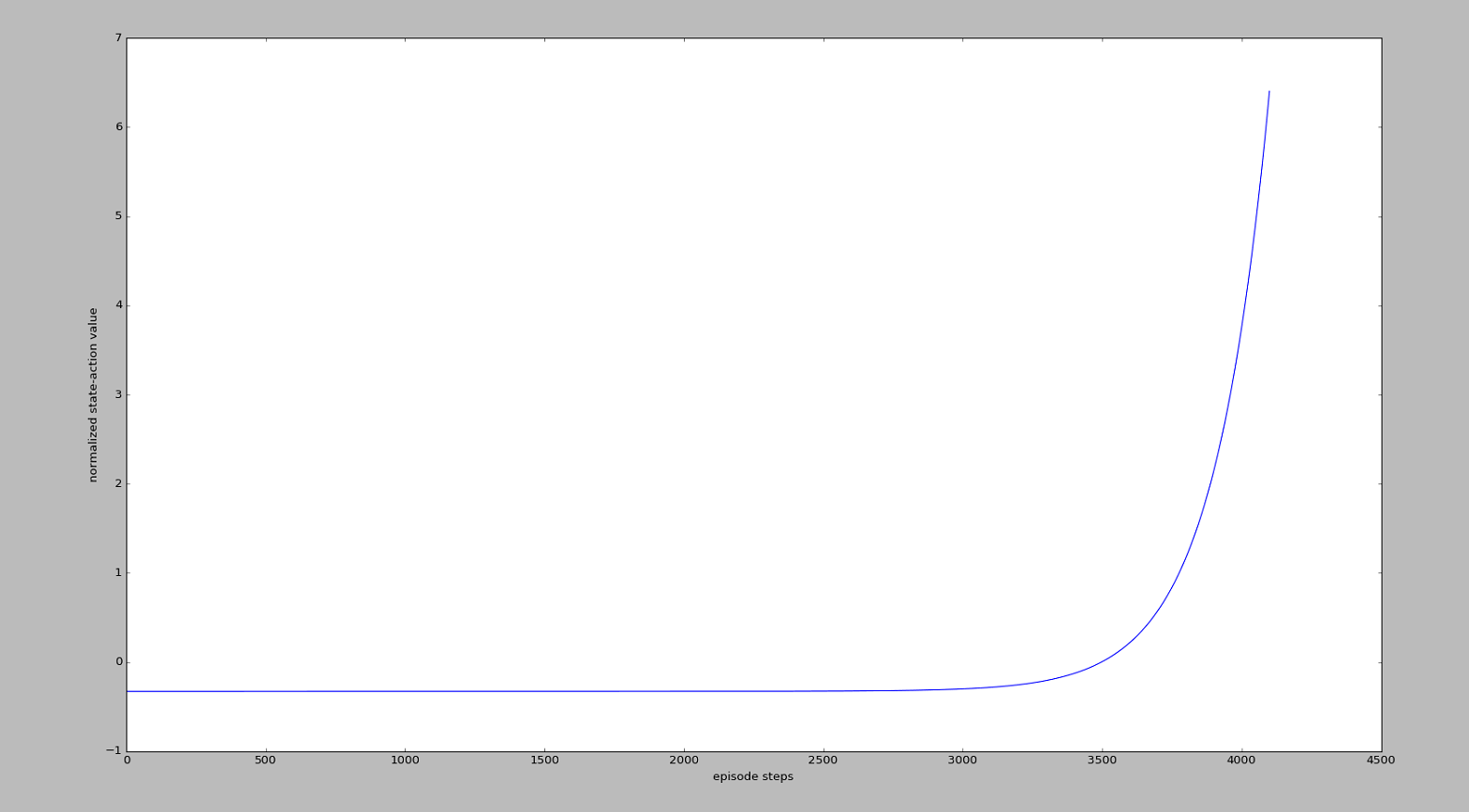
MountainCar这张图的意思是在说:
“请重视我这回合最后的一系列动作, 因为这一系列动作让我爬上了山. 而且请惩罚我开始的一系列动作, 因为这些动作没能让我爬上山”.
同样,通过$v_t$来诱导梯度下降的方向。
总结
和Value-Based相比,网络结构发生了很多变化,并且没有Target网络,也不需要DQN的经验池等等,代码简洁了很多,并且损失函数的优化器不一样。这个只是最基础的PG算法,下面将开始AC算法
在网络的代码中,PG在build_net、choose_action、store_transition处和之前的Value-Based方法有所改变,并且新添加了discount_and_norm_rewards函数