前言
针对前面PG算法的高方差问题,本篇博客将基于AC算法进行实现。其理论部分请点击DRL(六)
主要在莫烦代码的基础之上,进行更改
一、实验环境
主要使用两个环境进行训练测试,分别是CartPole环境和Pendulum环境。其中CartPole应用于softmax策略函数的离散行为空间,Pendulum应用于高斯策略函数的连续行为空间。
二、Actor-Critic算法
主要用$Qw(s,a)$来代替PG算法中的$v_t$,用来估计行为价值函数$ Q^{\pi\theta}(s,a)$,即$Qw(s,a) \approx Q^{\pi\theta}(s,a)$,该网络称为Critic网络。
- Critic:更新行为价值函数的参数$w$
- Actor:更新策略的参数θ,更新过程会受到Critic的价值函数的引导
Actor-Critic 的评估
Actor-Critic的评估一般有以下几种方法,主要变化的是$Q_w(s,a)$
(1)基于状态价值:这和之前的蒙特卡洛策略梯度REINFORCE方法一样,这时Actor的策略函数参数更新的法公式为:
(2)基于动作价值:在DQN中,我们一般使用的都是动作价值函数Q来做价值评估,这时Actor的策略函数参数更新的法公式为:
(3)基于TD($\lambda$)误差:一般都是基于后向TD($\lambda$)误差,是TD误差和效用迹E的乘积,这时Actor的策略函数参数更新的法公式是:
其中,TD误差$\delta(t) = R{t+1} + \gamma V(S{t+1}) - V(st)$,$E(t) = \gamma \lambda E{t-1} + \nabla\theta log \pi\theta (s_t,a_t)$
当$\lambda=0$时,就是普通TD方法,即$\theta = \theta + \alpha \nabla\theta log \pi\theta (s_t,a_t) \delta(t)$
(4)基于优势函数(基准函数Baseline):和之前Dueling DQN中的优势函数一样,其优势函数A的定义为:$A(S,A,w,\beta) = Q(S,A,w,\alpha,\beta) - V(S,w,\alpha)$,即动作价值函数和状态价值函数的差值,这时Actor的策略函数参数更新的法公式为:
本篇实验过程将基于第三种方法,基于TD($\lambda$)误差进行评估
三、代码部分
直接查看全部代码
3.1 代码组成
代码主要由四个py程序组成:其中,run_CartPole.py对应于actor_critic.py,表示对离散行为空间的训练;run_Pendulum.py对应于actor_critic_gaussian.py表示对连续行为空间的训练
程序架构:主要分为Actor和Critic两个类
1 | class Actor(object): |
3.2 softmax策略函数-离散行为空间
3.2.1 网络-actor-critic.py
Actor
训练过程中的一些注意的地方
- 输入:因为Actor可以单次训练,所以输入只需要是一个状态,一个动作和一个TD-Error
- 网络结构:和PG算法中的网络结构一样,使用一个双层的全连接神经网络
- 损失函数:在PG中loss = -log(prob) * vt,在这里只是将vt换成了由Critic计算出的时间差分误差TD-Error
- Actor训练:只需要将状态、动作以及时间差分值喂给网络就可以了
- 选择动作:和PG一样,根据softmax值进行选择
1 | class Actor(object): |
Critic
Critic要反馈给Actor一个时间差分值,来决定Actor选择动作的好坏,如果时间差分值大的话,说明当前Actor选择的这个动作的惊喜度较高,需要更多的出现来使得时间差分值减小。
时间差分计算:$\delta(t) = R{t+1} + \gamma V(S{t+1}) - V(s_t)$,$V(s_t)$表示将$s$状态输入到Critic网络中得到的Q值。因此Critic的输入也分三个,首先是当前状态,当前奖励,下一状态。为什么没有动作A?因为动作A是确定的,是由Actor选择的。
- 输入:当前状态,当前奖励,下一状态
- 网络结构:和Actor一样,是一个双层网络,网络最后输出V值
- 损失函数:$\delta(t) = R{t+1} + \gamma V(S{t+1}) - V(s_t)$
- Critic训练:将当前状态、当前奖励、下一状态喂给网络即可,并得到TD-Error的值,最后给Actor
1 | class Critic(object): |
3.2.2主函数-run_CartPole.py
和之前不一样的是,里面是单步训练
1 | env = gym.make('CartPole-v0') |
注意:
(1)为什么加入这个才能学习?
1 | if done: r = -20 #回合结束的惩罚 |
因为AC在每次更新时,只考虑前后两步,而环境里面的reward只有+1,所以为了体现前后两步的不同,在done的时候给一个-20的信号,让信号强度有所不同
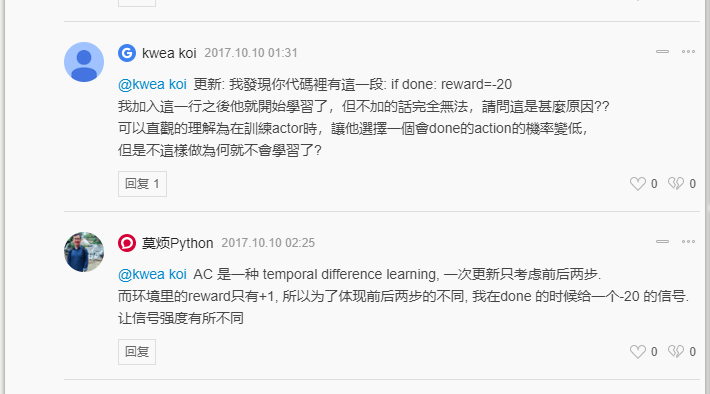
(2)求解TD-Error时,是否需要考虑done的情况?
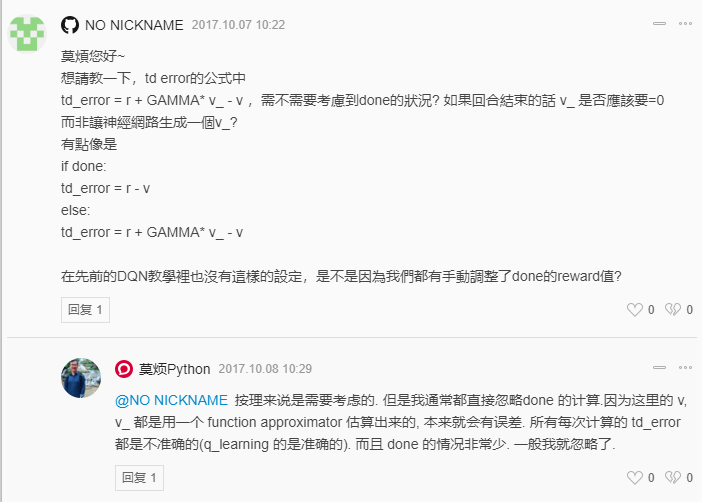
(3)log概率的代码?如果是下面被注释的那一行,则不太理解
和带有axis的值类似,若axis=0,则沿着纵轴进行操作;axis=1,沿横轴进行操作
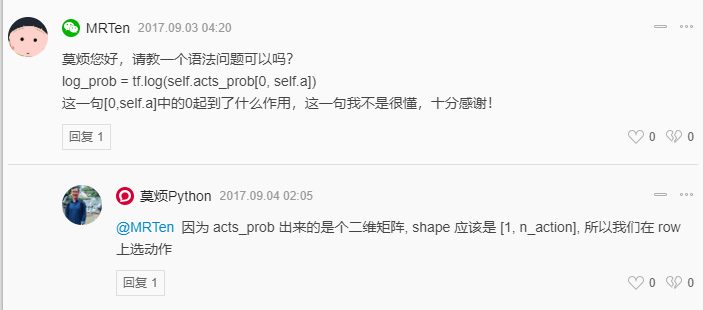
1 | #neg_log_prob = tf.log(self.all_act_prob[0, self.a]) |
(4)AC收敛好像没有PG快?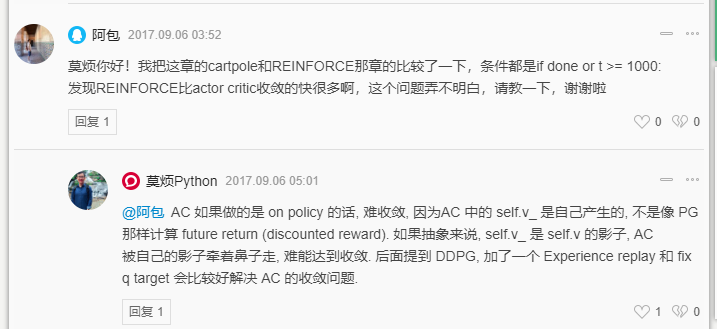
3.3 Gaussian策略函数-连续行为空间
3.3.1 网络-actor-critic-gaussian.py
1 | class Actor(object): |
3.3.2 主函数-run_Pendulum.py
1 | env = gym.make('Pendulum-v0') |
注意:
(1)添加了global_step变量,不太清楚干啥?
(2)这个连续行为的训练效果好像并不太好?
关于连续行为空间的,还是主要看DDPG和A3C吧
总结
Actor-Critic算法的思路很好,但是不太容易收敛,目前对AC算法进行改进,解决其难收敛的问题主要有DDPG和A3C算法,而且测试的AC在连续行为空间上的效果不太好