前言
Airsim的官方github上面其实提供了一些强化学习的训练demo,如drone的DQN训练、car的DQN训练,但是都是基于cntk进行实现的,而这一块我不熟悉,还是用我熟悉的Tensorflow进行训练测试,与drone的DQN训练目标不同,甚至由于是cntk相关实现,也没有去细看其官方训练demo。
但是其思想都差不多,因为都是基于DQN进行训练
一、问题定义
在AirSimNH.sh的场景下进行训练
1.1 目标
训练一个agent,从起点出发,沿着道路中心线飞行到正前方6米处的地方
1.2 马尔科夫状态过程
- 状态集:深度图像的灰度图集合(n种)
- 行为集:前行、左行、右行(3种)
- 转换函数:model free
- 奖励函数:
- 正面奖励:到达目标点范围:x属于[-4.5,7.5],y属于[-0.8,0.8],reward = 1
- 负面奖励:超出边界:x > 7.5 或者 abs(y) >2,reward = -1
- 生活成本:每走一步,reward = -0.01
- 起始状态:(0,0,-3)
- 结束状态:
- 到达目标点
- 超出边界
- 20步强制结束当前episode
二、代码部分
直接查看所有代码
(1)经验缓冲池:ReplayBuffer.py
1 | from collections import deque |
(2)环境:AirsimEnv.py
1 | goals = [6,2] |
(3)DQN训练:dqn.py
1 | from AirsimEnv import Env |
(4)random_test.py:
1 | from AirsimEnv import Env |
(5)dqn_test.py
1 | from AirsimEnv import Env |
三、训练数据和测试数据
(1)DQN训练数据
| 迭代范围 | 正面奖励次数 | 负面奖励次数 | 强制截止次数 | 单位:千 |
|---|---|---|---|---|
| 1-1000 | 215 | 764 | 20 | 1 |
| 1000-2000 | 122 | 869 | 8 | 2 |
| 2000-3000 | 446 | 549 | 4 | 3 |
| 3000-4000 | 621 | 366 | 12 | 4 |
| 4000-5000 | 716 | 273 | 10 | 5 |
| 5000-6000 | 704 | 287 | 8 | 6 |
| 6000-7000 | 734 | 262 | 3 | 7 |
| 7000-8000 | 766 | 222 | 11 | 8 |
| 8000-9000 | 766 | 222 | 8 | 9 |
| 9000-10000 | 768 | 225 | 6 | 10 |
| 1-10000 | 5866 | 4044 | 90 | 总计 |
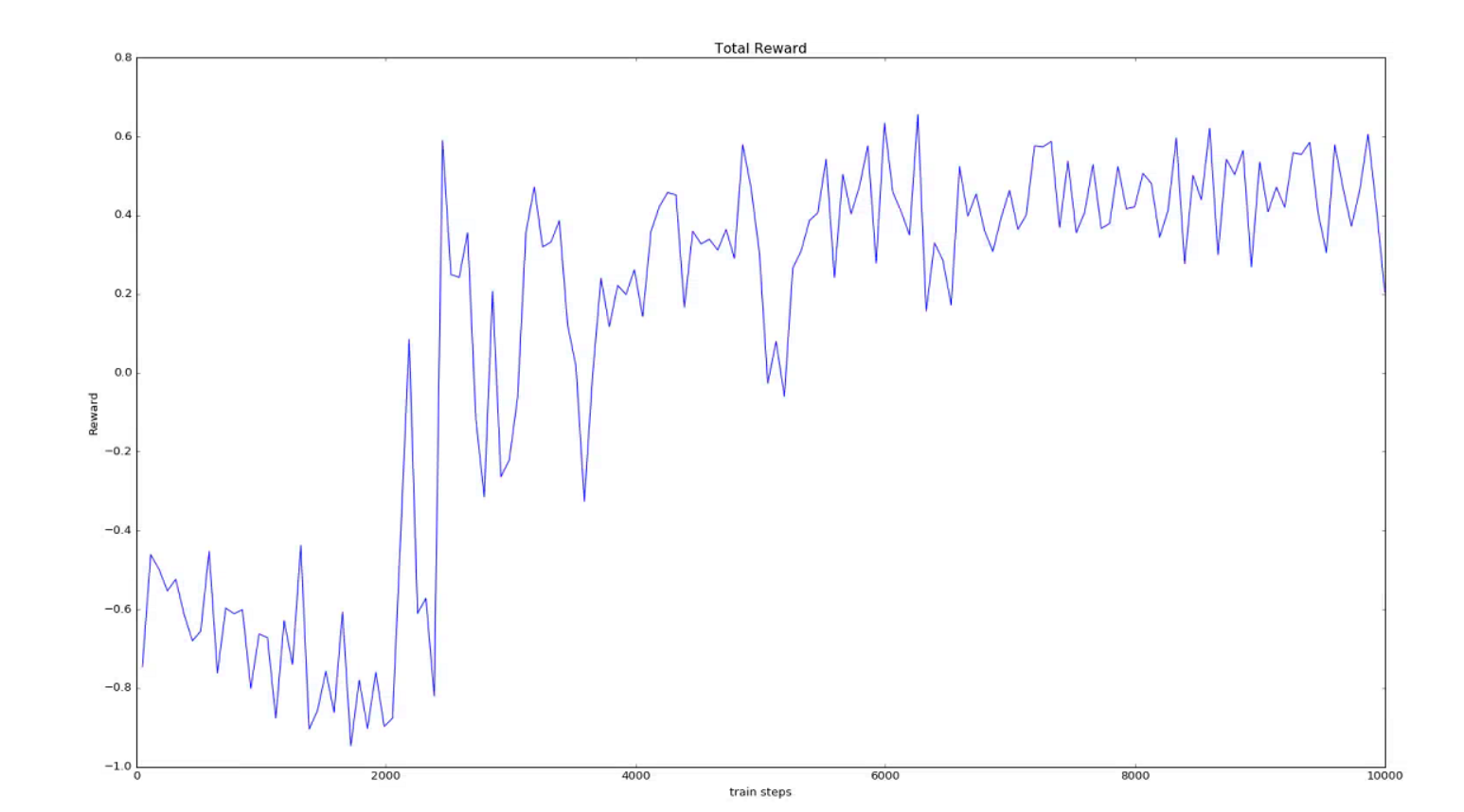
训练过程中累积奖励图(每50个episode的reward取均值)
(2)随机飞行测试数据
| 迭代范围 | 正面奖励次数 | 负面奖励次数 | 强制截止次数 | 单位:千 |
|---|---|---|---|---|
| 1-1000 | 235 | 734 | 31 | 1 |
(3)DQN网络测试数据
| 迭代范围 | 正面奖励次数 | 负面奖励次数 | 强制截止次数 | 单位:千 |
|---|---|---|---|---|
| 1-1000 | 999 | 1 | 0 | 1 |
训练过程中,其值稳定在770左右,而测试的时候,其值接近1000,可能是因为训练过程中存在10%的概率随机选择行为,因此训练的准确性没有测试的准确性高。
测试和训练的场景都是同一个场景
在32GB 1080TI显卡上训练接近28个小时左右
1 | episode 999 is done |
总结
通过直接调用API完成了DQN算法的一个简单验证,训练的目标很简单。但将代码封装为ros后,训练效果却很差。在ros的控制下,使用RGB图训练过,也使用过深度图训练过,训练效果都不太好。暂时还没太弄清楚其原因。不过在ros的转换下,其深度图显示的有点问题。和原图不提啊一样