前言
DDPG算法主要是将DPG和DQN的特性结合起来,和前面的AC算法相比,Actor输出的不在是行为的概率,而是具体的行为,用于连续动作的预测。其理论部分请阅读DRL论文阅读(七)和DRL论文阅读(八)
本文的代码基于莫烦大神的代码,进行少量修改而成(参考的是简单版,测试过程中,莫烦的DDPG初始版本还存在一点问题)
一、实验环境
主要使用Pendulum环境,且采用的是连续行为空间
二、DDPG算法
DDPG框架图
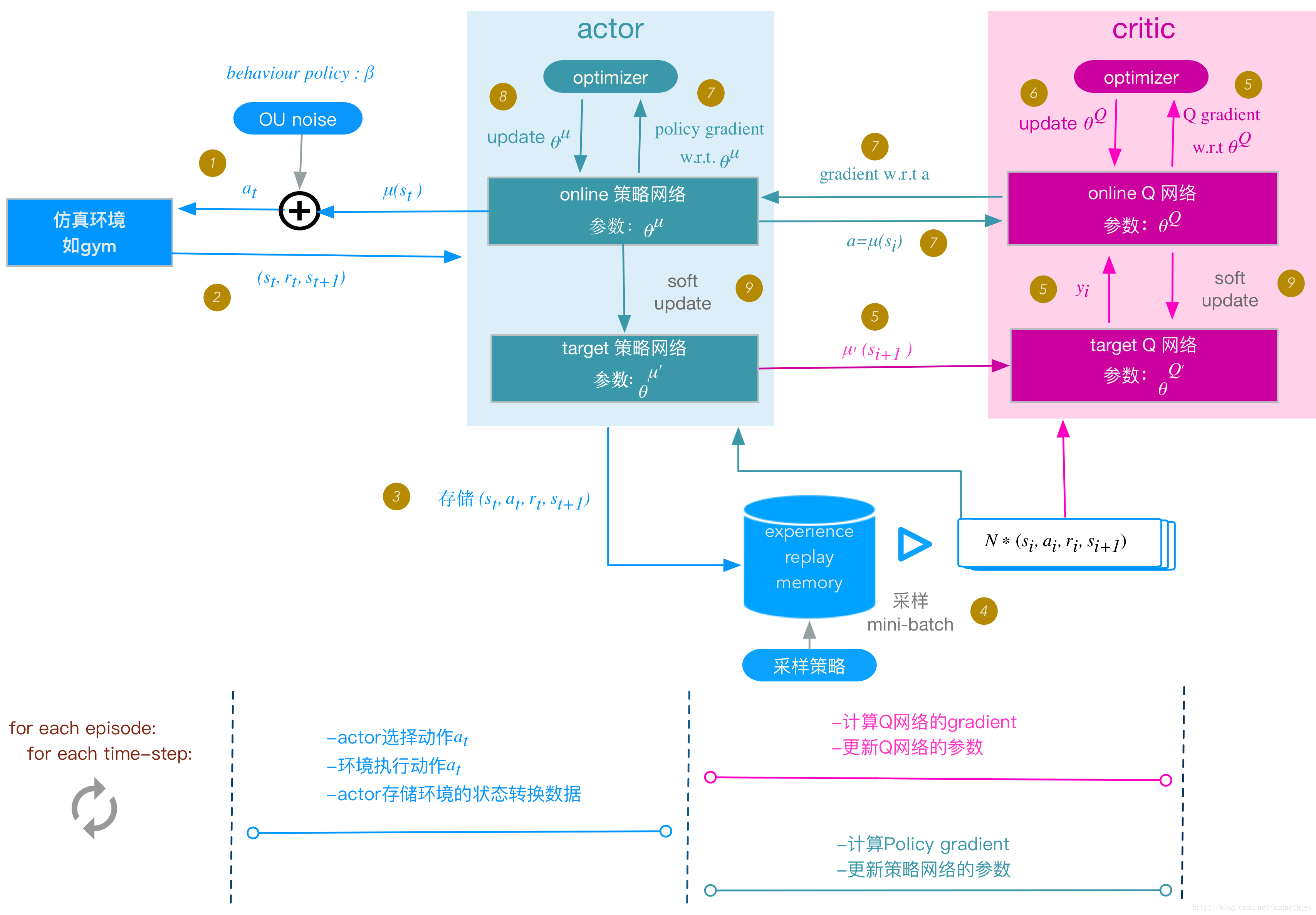
DDPG算法流程

三、代码部分
直接查看所有代码
3.1 代码组成
代码主要由两部分组成,一部分是关于DDPG算法结构的py程序,另一部分是关于gym的运行环境
程序架构
1 | class DDPG(object): |
3.2 网络-DDPG.py
init函数、Actor网络和Critic网络