一、建造者模式
定义:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
主要作用:在用户不知道对象的建造过程和细节的情况下,就可以直接创建复杂的对象
1、简单例子说明
1、工厂(建造者模式):负责制造汽车(组装过程和细节在工厂内)
2、汽车购买者(用户):用户只需要说出需要的型号(对象的类型和内容),然后直接购买就可以使用(不需要知道汽车是怎么组装的(车轮、车门、发动机、方向盘等等))
以造房为例:
假设造房简化为如下步骤:
1、地基
2、钢筋工程
3、铺电线
4、粉刷
则其流程基本可以概括为:建筑公司或工程承包商(指挥者)—>指挥工人(具体建造者)—>造房子(产品),最后验收
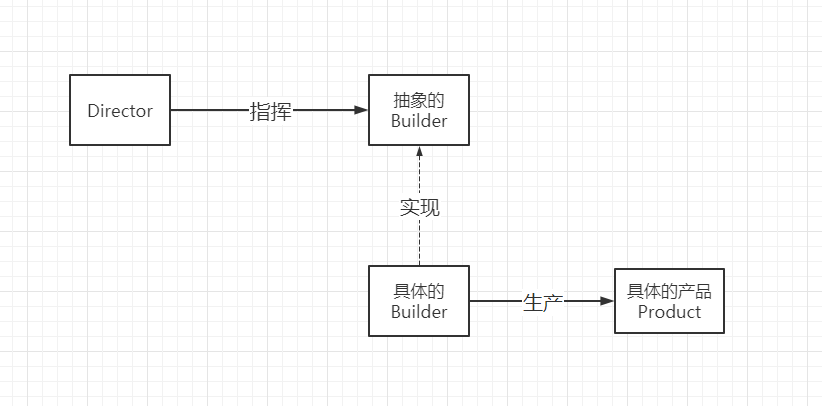
2、建筑者模式流程图
如下图所示,主要由指挥者指挥建造者来生产产品
假设下图中抽象的Builder为楼:则具体的Builder(工人)可以建造不同的产品,比如平房、别墅等等。
这也就对应了前面所说的:同样的构建过程可以创建不同的表示
3、代码实例(一)
3.1 Product类:产品类
1 | //产品:房子 |
3.2 Builder类:抽象类
1 | //抽象的建造者:方法 |
分析:
为什么要使用抽象类?
楼房是千差万别的,楼房的外形、层数、内部房间的数量等等,但对于建造者来说,抽象出来的建筑流程是确定的,而每个流程实现的具体细节则是经常变化的
3.3 Worker类:工人类
1 | //具体的建造者:工人 |
3.4 Director类:指挥类
1 | //指挥:核心。负责指挥构建一个工程,工程如何构建,由它决定 |
3.5 Test类:测试类
1 | //测试类 |
结果:
2
3
4
5
钢筋工程
铺电线
粉刷
Product{buildA='地基', buildB='钢筋工程', buildC='铺电线', buildD='粉刷'}分析:
在指挥类中,按照不同的顺序构建房子,则最终的输出结果不一样,因此能将一个复杂对象的构建与它的表示分离
在测试类中,通过不同的工人,可以创造不同的房子,但其流程不变,也就是:使得同样的构建过程可以创建不同的表示。
4、代码实例(二)
代码实例(一)是建造者模式的常规用法,指挥类(Director)在建造者模式中具有很重要的作用,它用于指导具体构建者如何构建产品,控制调用先后次序,并向调用者返回完整的产品类,但有些情况下需要简化系统结构,可以把Director和抽象建造者进行结合。
比如:麦当劳的套餐,服务员(具体建造者)可以随意搭配任意几种产品(零件)组成一款套餐(产品),然后出售给客户。比第一种方式少了指挥者,主要是因为第二种方式把指挥者交给用户来操作,使得产品的创建更加简单灵活。
4.1 Product类:产品类
1 | //产品:套餐 |
4.2 Builder类:抽象类
1 | //建造者 |
4.3 Worker类:建造类
1 | //具体的建造者 |
4.4 Test类:测试类
1 | public class Test { |
结果:
建造者模式优缺点
优点:
1、产品的建造和表示分离,实现了解耦。使用建造者模式可以使客户端不必知道产品内部组成的细节。
2、将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰。
3、具体的建造者之间是相互独立的,这有利于系统的扩展。增加新的具体建造者无需修改原有类库的代码,符合“开闭原则”。
缺点:
1、建造者模式所创建的产品一般具有较多的共同点,其组成部分相似;如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
2、如果产品的内部变化复杂,可能会导致需要定义很多具体建造者来实现这种变化,导致系统变得很庞大。
建造者模式VS抽象工厂模式
1、与抽象工厂模式相比,建造者模式返回一个组装好的完整产品。而抽象工程模式返回一系列相关的产品,这些产品位于不同的产品等级结构,构成了一个产品簇。
2、在抽象工厂模式中,客户端实例化工厂类,然后调用工厂方法获取所需产品对象。而在建造者模式中,客户端可以不直接调用建造者的相关方法,而是通过指挥者类来指导如何生成对象,报告对象的组装过程和建造步骤,它侧重于一步步构造一个复杂对象,返回一个完整的对象。
3、如果将抽象工厂模式看成汽车配件生产工厂,生产一个产品簇的产品。那么建造者模式就是一个汽车组装工厂,通过对不同的组件可以返回一辆完整的汽车。
总结
产品类:一般是一个较为复杂的对象,也就是说创建对象的过程比较复杂,一般会有比较多的代码量。
抽象建造者:引入抽象建造者的目的,是为了将建造的具体过程交与它的子类来实现。这样更容易扩展。一般至少会有两个抽象方法,一个用来建造产品,一个用来返回产品。
建造者:实现抽象类的所有未实现的方法,具体来说一般是两项任务:组件产品,返回组建好的产品。
指挥类:负责调用适当的建造者来组建产品,指挥类一般不与产品类发生依赖关系,与指挥类交互的是建造者类。一般来说,指挥类被用来封装程序中易变的部分。
二、原型模式
原型模式用于创建重复的对象,同时又能保证性能。
1、代码实例
1.1 浅克隆
1.1.1 Video类—原型类
主要:
1、实现一个接口:Cloneable
2、重写一个方法:clone()
1 | import java.util.Date; |
1.1.2 Bilibili类
1 | import java.util.Date; |
结果:
2
3
4
v1=>hash:1735600054
v2=>Video{name='狂神说Java', createDateTime=Sat Jun 19 12:34:10 CST 2021}
v2=>hash:21685669但这种初始简单克隆模式存在一个问题,即该模式是一个浅克隆。
浅克隆:新对象的基础类型的变量值与原对象相同,而特殊对象,即非八大基本类型的对象与原对象指向同一内存空间,不管新老对象谁对这段内存空间进行操作都会影响到另一个。
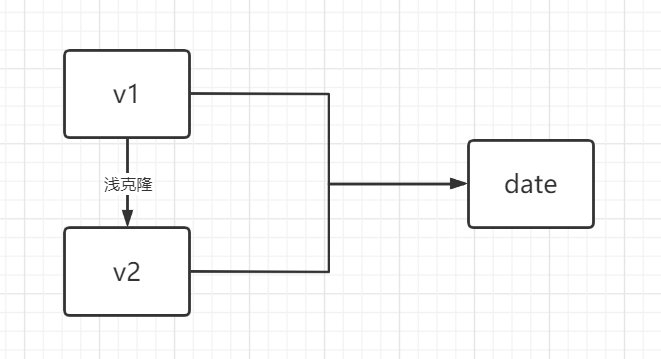
如果将上诉的Bilibili类进行修改,如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class Bilibili {
public static void main(String[] args) throws CloneNotSupportedException {
//原型对象 v1
Date date = new Date();
Video v1 = new Video("狂神说Java",date);
//调用clone方法需要抛出异常CloneNotSupportedException
Video v2 = (Video) v1.clone(); // v1 克隆v2
System.out.println("v1=>"+v1);
System.out.println("v2=>"+v2);
System.out.println("=====================");
date.setTime(123465645);
System.out.println("v1=>"+v1);
System.out.println("v2=>"+v2);
}
}结果:
2
3
4
5
v2=>Video{name='狂神说Java', createDateTime=Sat Jun 19 12:47:32 CST 2021}
=====================
v1=>Video{name='狂神说Java', createDateTime=Fri Jan 02 18:17:45 CST 1970}
v1=>Video{name='狂神说Java', createDateTime=Fri Jan 02 18:17:45 CST 1970}分析:
修改date的值后,发现v1和v2的date值全部改变,这与我们所期望的不符,即一个修改,不影响另一个值
1.2 深克隆
深克隆:新对象除了与老对象的八大基本类型的赋值一致以外,其类类型的对象在保证赋值一致的基础上,指向的是一段新的内存空间。
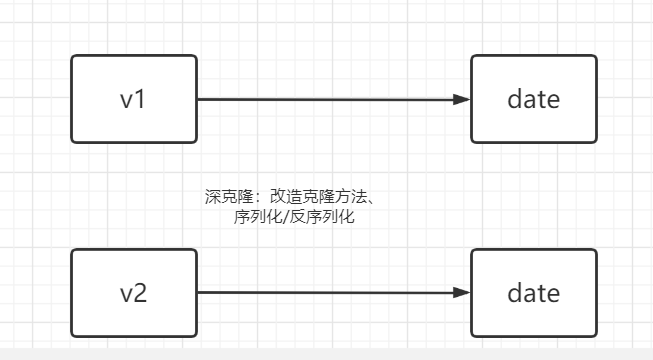
通过修改clone方法的模式,实现深克隆
1.2.1 Video类—原型类
1 | import java.util.Date; |
1.2.2 Bilibili类
1 | import java.util.Date; |
结果:
2
3
4
5
v2=>Video{name='狂神说Java', createDateTime=Sat Jun 19 23:15:04 CST 2021}
=====================
v1=>Video{name='狂神说Java', createDateTime=Tue Jan 06 17:17:58 CST 1970}
v2=>Video{name='狂神说Java', createDateTime=Sat Jun 19 23:15:04 CST 2021}分析:
从结果中,就可以看出v1和v2的时间不同,因此,实现了原型的深克隆
序列化&反序列化
概念:
- 序列化:把Java对象转换为字节序列的过程
- 反序列化:把字节序列恢复为Java对象的过程
序列化用途:
- 把对象得到的字节序列永久地保存到硬盘上,通常存放在一个文件中(持久化对象)
- 在网络上传送对象的字节序列(网络传输对象)
序列化使用:必须实现Serializable接口
1.3 序列化实现深克隆
1.3.1 Video类—原型类
1 | import java.io.*; |
1.3.2 Bilibili类
1 | import java.io.IOException; |
结果:
2
3
4
5
v2=>Video{name='ldg原型', createDateTime=Tue Jun 22 22:35:27 CST 2021}
======================
v1=>Video{name='ldg原型', createDateTime=Thu Jan 01 20:39:07 CST 1970}
v2=>Video{name='ldg原型', createDateTime=Tue Jun 22 22:35:27 CST 2021}分析:
通过序列化与反序列化的方式,也可以实现深克隆
总结
浅克隆:克隆对象的值相同,且克隆对象指向的内存空间也相同
可通过实现Cloneable接口和重写clone方法实现
深克隆:克隆对象的值相同,且克隆对象指向的内存空间不相同
实现Cloneable接口和重写clone方法实现
在重写clone方法时,对子对象也需要克隆。比如A1包含A2,要想真正实现A1的深克隆,则还需要克隆A2
通过序列化和反序列化的方式实现克隆
需要实现Serializable接口
- 序列化
1
2
3
4//序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos); //需要抛出IO异常
oos.writeObject(this);//将当前这个对象以对象流的方式输出反序列化
1
2
3
4//反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
Video v1 = (Video)ois.readObject();//需要抛出ClassNotFoundException异常