一、数据库
1、Mysql的逻辑分层
连接层->服务层->引擎层->存储层
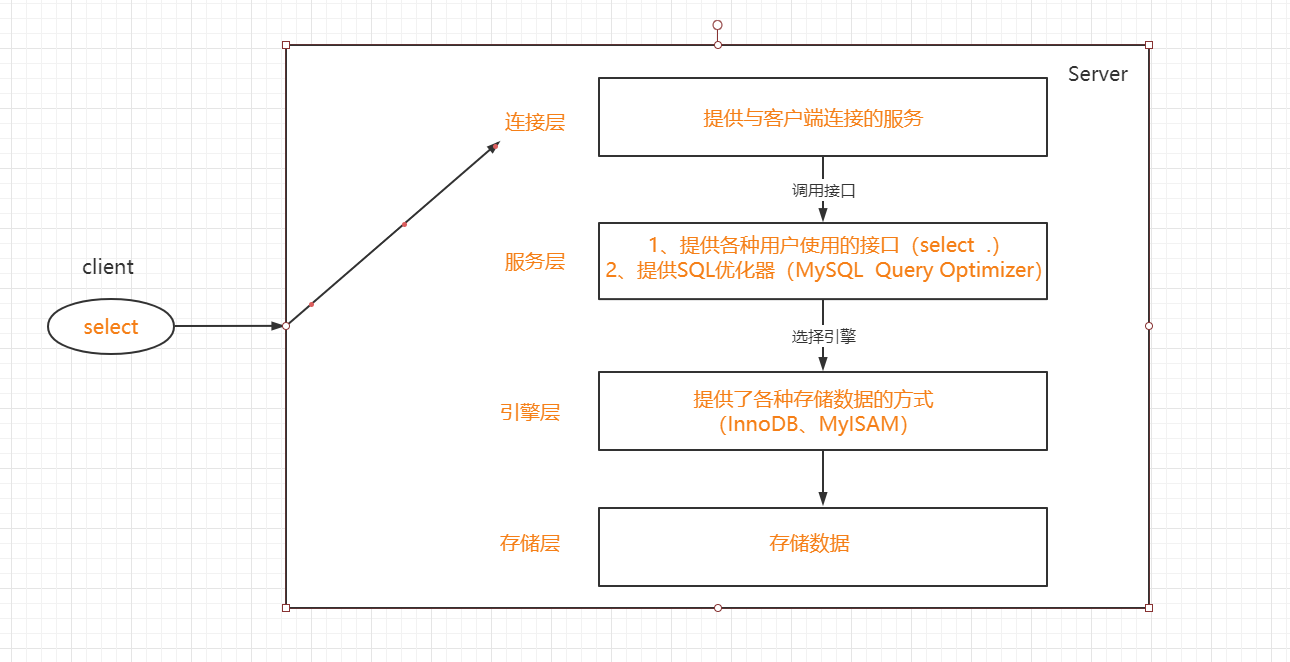
分析:
在服务层中,MySQL提供了一个SQL优化器,可以将SQL语句进行优化,并且改变其执行的顺序结构,但最终的结果不变。
比如,SQL语句顺序为 a b c,SQL优化器之后的为 b a c
简单说明InnoDB和MyISAM的区别方式
- InnoBD(默认):事物优先,适合高并发操作,行锁
- MyISAM:性能优先,表锁
2、SQL优化
原因
性能低、执行时间太长、等待时间太长、SQL语句欠佳(连接查询)、索引失效、服务器参数设置不合理(缓冲、线程数)
2.1 SQL语句欠佳
编写过程
select 后是输出
from 后是 获取数据
where 后是过滤
group by 后是分组
- group by id,按照id进行分组
- 分组后,如果遇到select,那么输出的是每一组的第一行数据
- group by还可以和聚集函数放在一起
- 聚集函数:count()、sum()、max()、min()、avg()、group_concat()
having 后是过滤
order by 后是排序
limit 后是限定个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >解析过程
1
2
3
4
5
6
7
8
9
10FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
3、连接查询
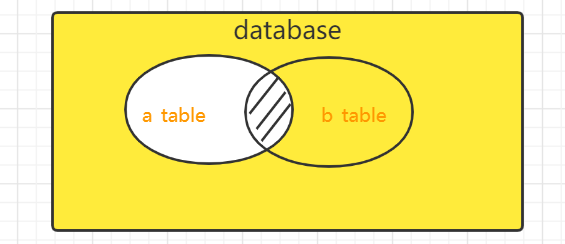
3.1 inner join 内连接查询
关键字:inner join on
组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
1 | select * from a_table a inner join b_table b on a.id = b.id; |
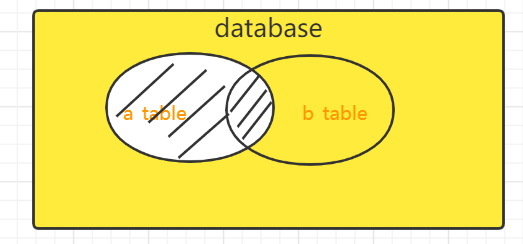
3.2 left join 左连接查询
关键字:left join on / left outer join on
left join是left outer join的简写,它的全称是左外连接,是外连接中的一种。左(外)链接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL
1 | select * from a_table left join b_table on a.id = b.id; |
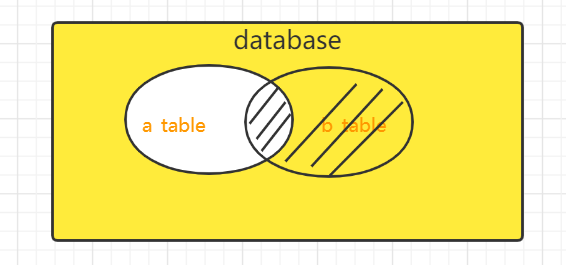
3.3 right join 右连接查询
关键字:right join on / right outer join on
right join 是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
1 | select * from a_table right join b_table on a.id = b.id; |
3.4 union 全连接
关键字:union / union all
注意事项:
- 通过union连接的sql,他们分别单独取出的列数必须相同;
- 不要求合并的表列名称相同时,以第一个sql表列名为准;
- 使用union时,完全相等的行,将会被合并,由于合并比较耗时,一般不直接使用union进行合并,而是通常采用union all进行合并;
- 被union连接的sql子句,单个子句中不用写order by,因为不会有排序的效果。但可以对最终的结果进行排序
1 | # union 自动去掉完全重复的数据 |
4、查询
创建库
2
create database test;创建表
2
create table students(id INT,name VARCHAR(100),age INT,height FLOAT,gender VARCHAR(100),class_id INT,PRIMARY KEY(id));给表中增加数据
2
3
4
5
6
7
8
9
10
11
12
13
14
15
insert into students values(1,"小明",18,180.00,"女",1);
insert into students values(2,"小月月",18,180.00,"女",2);
insert into students values(3,"彭于晏",29,185.00,"男",1);
insert into students values(4,"刘德华",59,175.00,"男",2);
insert into students values(5,"黄蓉",38,160.00,"女",1);
insert into students values(6,"凤姐",28,150.00,"保密",2);
insert into students values(7,"王祖贤",18,172.00,"女",1);
insert into students values(8,"周杰伦",36,NULL,"男",1);
insert into students values(9,"陈坤",27,181.00,"男",2);
insert into students values(10,"刘亦菲",25,166.00,"女",2);
insert into students values(11,"金星",33,162.00,"中性",3);
insert into students values(12,"静香",12,180.00,"女",4);
insert into students values(13,"郭靖",12,170.00,"男",4);
insert into students values(14,"周姐",34,176.00,"女",5);
4.1 模糊查询
1 | -- 查询姓名中以“小”开始的名字 |
4.2 范围查询
1 | -- in(12,18,34) 表示在一个非连续的范围内 not in |
4.3 聚合函数
1 | -- 总数 count |
4.4 分组
假设想要知道这样的一种情况,计算每个男性的姓名和平均身高,使用如下sql语句会报错,因此为了解决这种情况,需要使用到分组
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
select name,round(avg(height),2) from students where gender = "男";
-- group by
-- 按照性别分组,查询所有的性别
select gender from students GROUP BY gender;
之逻辑分层-存储引擎/截图-16311958882171.png)
疑问1:
select gender from students GROUP BY gender; 和 select DISTINCT(gender) from students ;有什么区别?
之逻辑分层-存储引擎/截图-16311959071312.png)
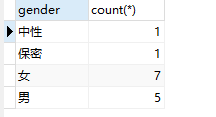
回答1:当想知道每一个性别的人数是多少时,可以结合聚合函数一起使用
```sql
-- 计算每个性别中的人数
select gender,count(*) from students GROUP BY gender;
1 | -- group_concat |

1 | select gender,GROUP_CONCAT(name,"_",age,"_",id) from students where gender = "男" GROUP BY gender; |

1 | -- having |

4.5 排序
1 | -- order by |
4.6 分页
1 | -- limit start,count 从start的下标开始查询出count个 |
4.7 连接查询
(1)造数据
2
3
4
5
create table classes(id INT,name VARCHAR(100),PRIMARY KEY(id));
insert into classes values(1,"c#课程");
insert into classes values(2,"Java课程");
insert into classes values(3,"Python课程");
4.7.1 内连接
1 | -- inner join ...on |
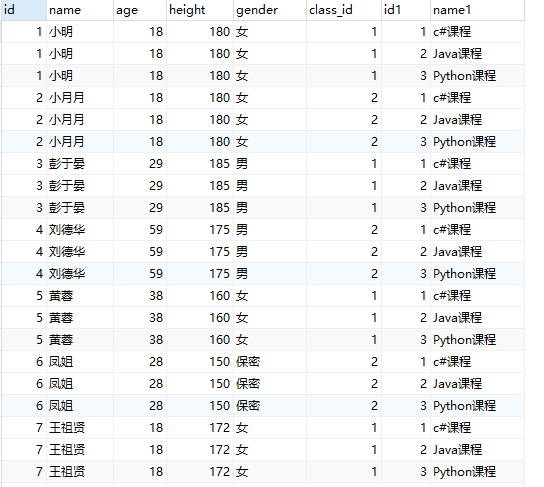
1 | select s.*,c.name from students as s inner join classes as c on s.class_id = c.id; |
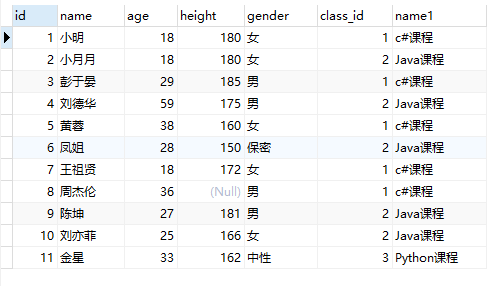
4.7.2 左连接
1 | select s.*,c.name from students as s left join classes as c on s.class_id = c.id; |
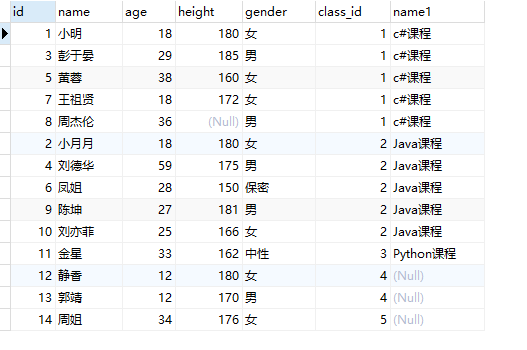
4.7.3 右连接
将左连接中的左表和右表互换即可
4.8 自关联
问题描述:
实现全国三级城市联动select选择
按照省、市、区进行分类,会设计三个表,表有些多余,重复,但省份中没有p_id这样的字段

可以将身份也添加一个p_id,设计为空即可,可以将下列三个表进行融合

使用一个表,然后利用id进行关联,这种在一个表内的设计就是自关联

表数据创造
1 | create table areas(aid int primary key,atitle varchar(20),pid int); |
查询(根据省名查询)
1 | select * from areas as province inner join areas as city on city.pid = province.aid having province.atitle = "山东省"; |
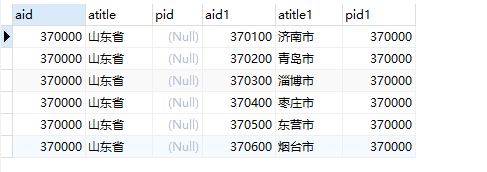
1 | select province.atitle,city.atitle from areas as province inner join areas as city on city.pid = province.aid having province.atitle = "山东省"; |
1 | select province.atitle,city.atitle from areas as province inner join areas as city on city.pid = province.aid having province.atitle = "山东省"; |
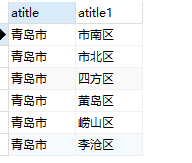
1 | select province.atitle,city.atitle from areas as province inner join areas as city on city.pid = province.aid having province.atitle = "青岛市"; |
4.9 子查询
子查询用的越少,sql效率越高
1 | -- 查询最高的男生信息 |

4.10 数据库设计—三范式
4.10.1 第一范式(1NF)
强调的是列的原子性,即列不能够在分成其他几列。
考虑到这样的一个表:【联系人】(姓名,性别,电话),如果在实际场景中,一个联系人有家庭电话和公司电话,那么这种表结构设计就没有达到1NF。 要符合1NF我们只需把列(电话)拆分,即【联系人】(姓名,性别,家庭电话,公司电话)

4.10.2 第二范式(2NF)
首先是1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
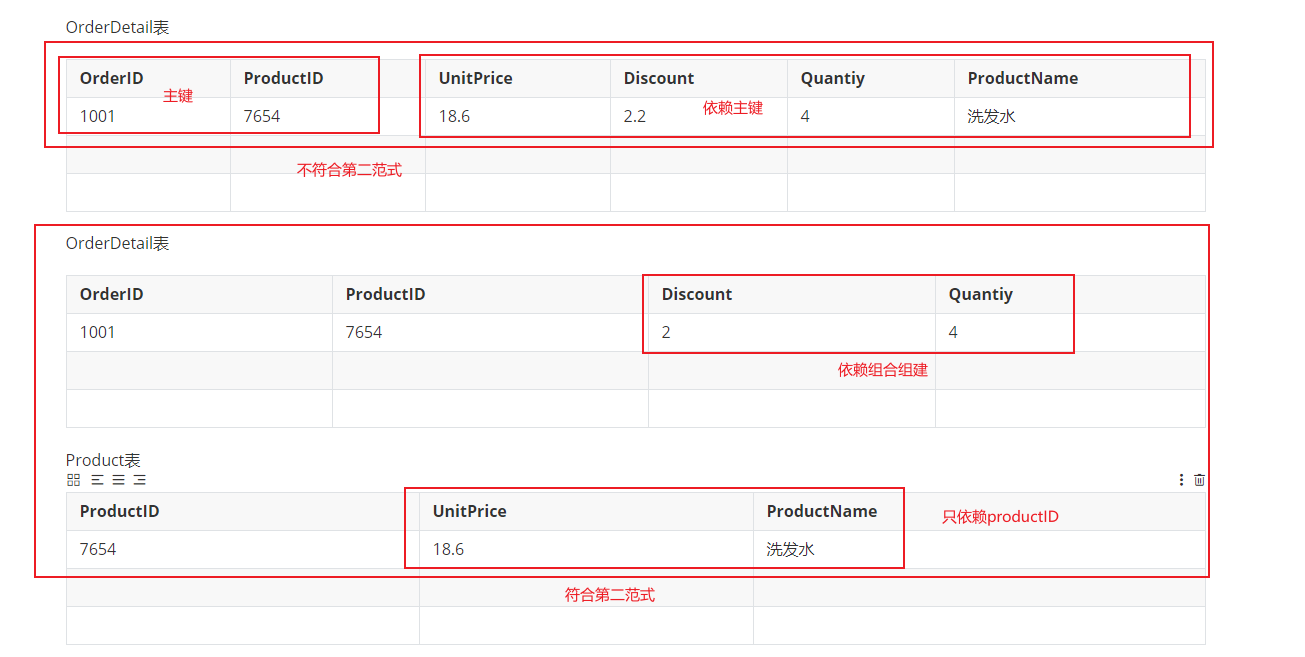
考虑一个订单明细表:【OrderDetail】(OrderID、ProductId、UnitPrice、Discount、Quantiy、ProductName)。因为我们知道在一个订单中可以订购多个产品, 所以单单一个OrderID是不足以成为主键的,主键应该是(OrderID、ProductID)。显而易见Discount(折扣)、Quanity(数量)完全依赖(取决于)主键(OrderID、ProductID), 而UnitPrice、ProductName只依赖于ProductID,所以OrderDetail表不符合2NF,不符合2NF的设计容易产生冗余数据 可以把【OrderDetail】表拆分为【OrderDetail】(OrderID、ProductId、Discount、Quantiy)和【Product】(ProductId、UnitPrice、Discount)来消除 订单表中UnitPrice、Discount多次重复的情况。
4.10.3 第三范式(3NF)
首先是2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列A依赖于非主键列B,非主键列B依赖于主键的情况。
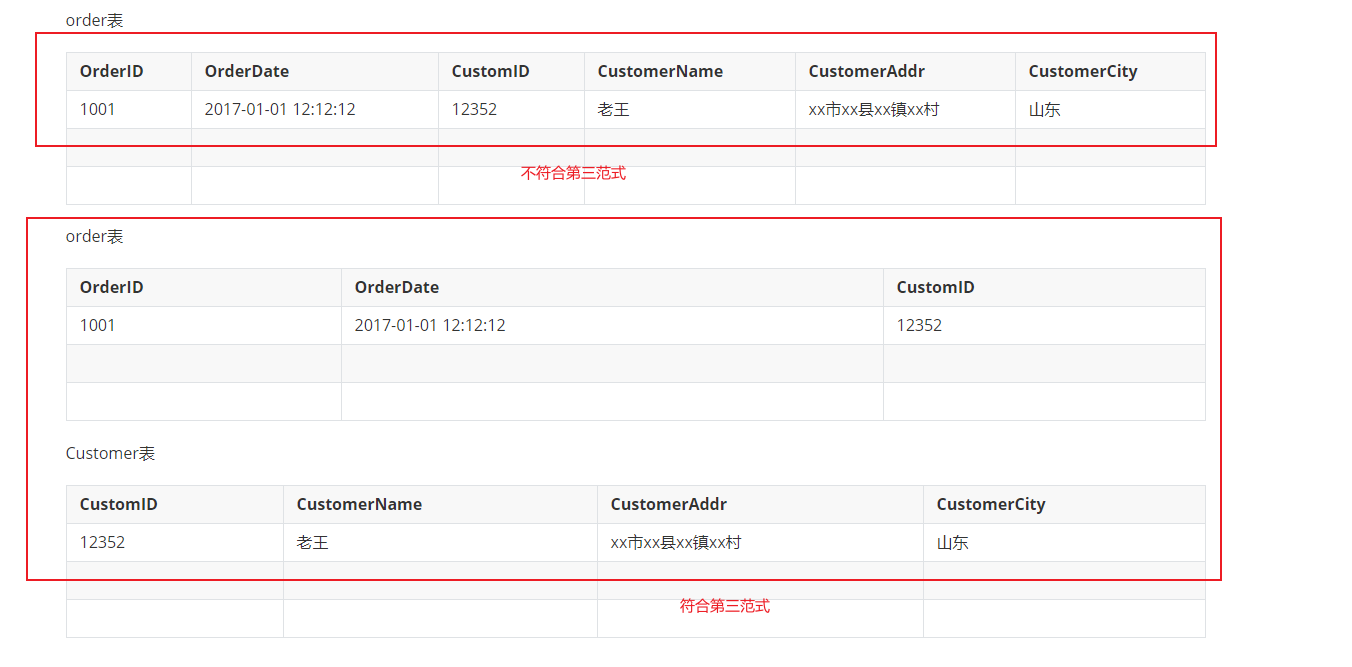
考虑一个订单表:【Order】(OrderID、OrderDate、CustomerID、CustomerName、CustomerAddr、CustomerCity) 主键是OrderID,其中OrderDate、CustomerID、CustomerName、CustomerAddr、CustomerCity等非主键列都完全依赖于主键OrderID,所以符合2NF,不过问题是 CustomerName、CustomerAddr、CustomerCity直接依赖的是CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才能依赖于主键,所以不符合3NF。 通过拆分【Order】为【Order】(OrderID、OrderDate、CustomerID)和【Customer】(CustomerID、CustomerName、CustomerAddr、CustomerCity)从而达到3NF。 第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键在于 2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分。3NF:非主键列是否直接依赖于主键,还是直接依赖于非主键列。
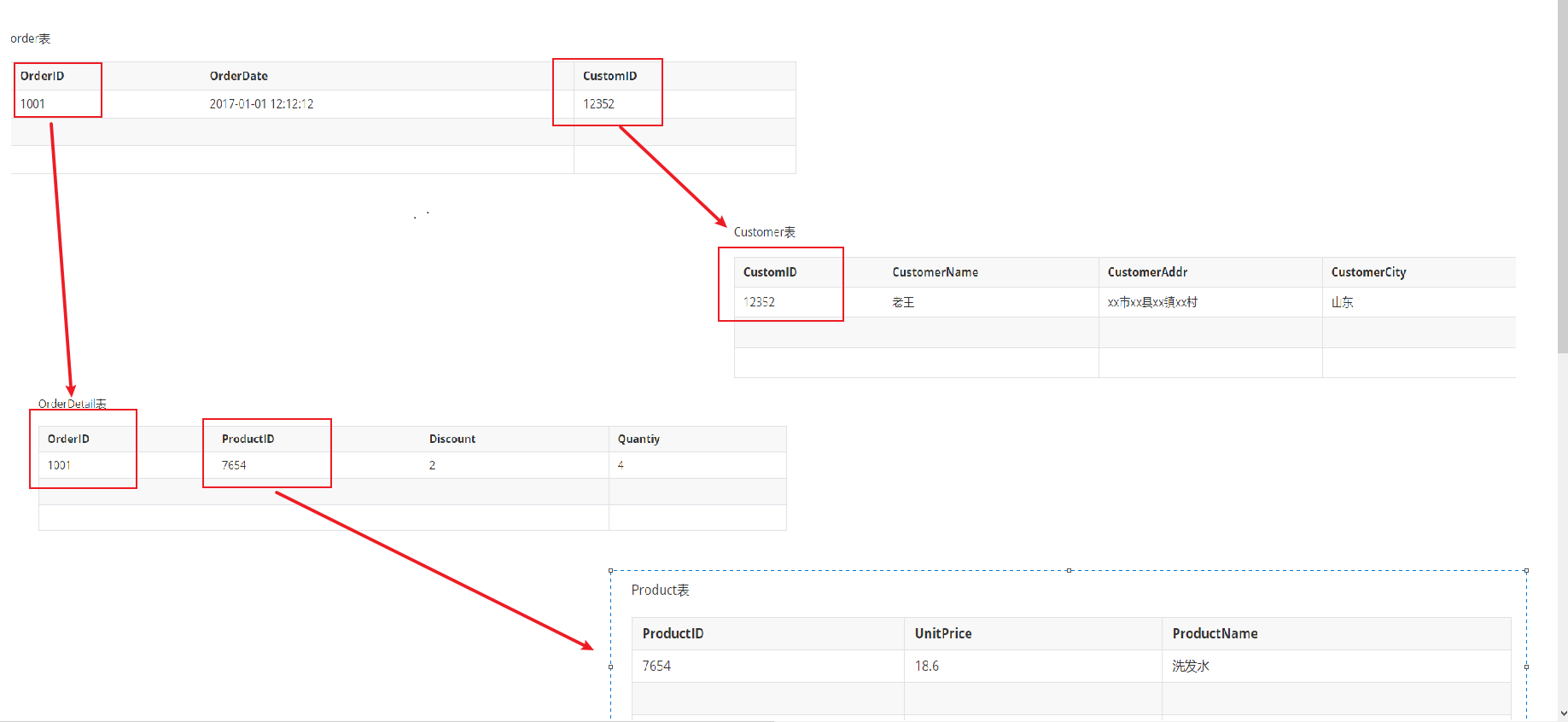
最终表结构
4.11 ER模型
E表示entry,实体,设计实体就像定义一个类一样,指定从哪些方面描述对象,一个实体转换为数据库中的一个表
R表示relationship,关系,关系描述两个实体之间的对应规则,关系的类型包括一对一、一对多、多对多
关系也是一种数据,需要通过一个字段存储在表中
(1)实体A对实体B为1对1,则在表A或表B中创建一个字段,存储另一个表的主键值
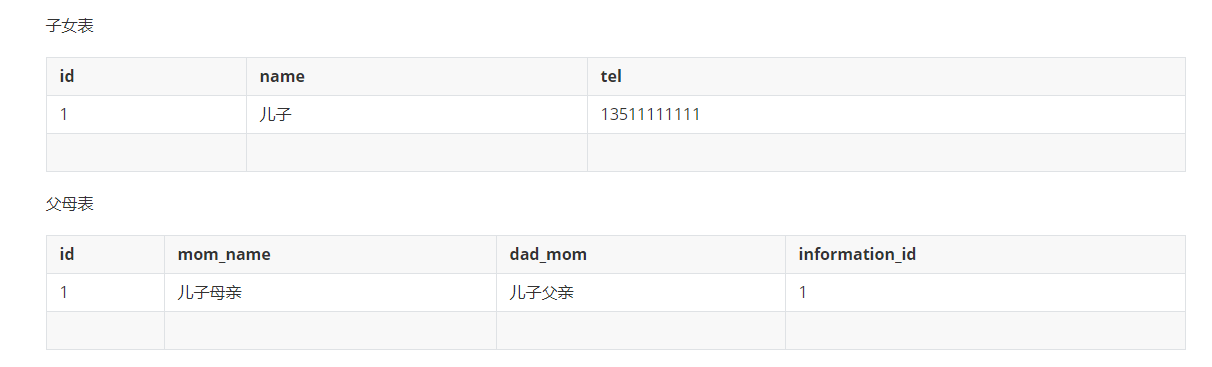
(2)实体A对实体B为1对多:在表B中创建一个字段,存储表A的主键值
A表中的一条数据对应B表中的一条数据
B表中的一条数据对应A表中的多条数据
假设多一个女儿时,需要在子女表中多添加一条数据,即如下情况
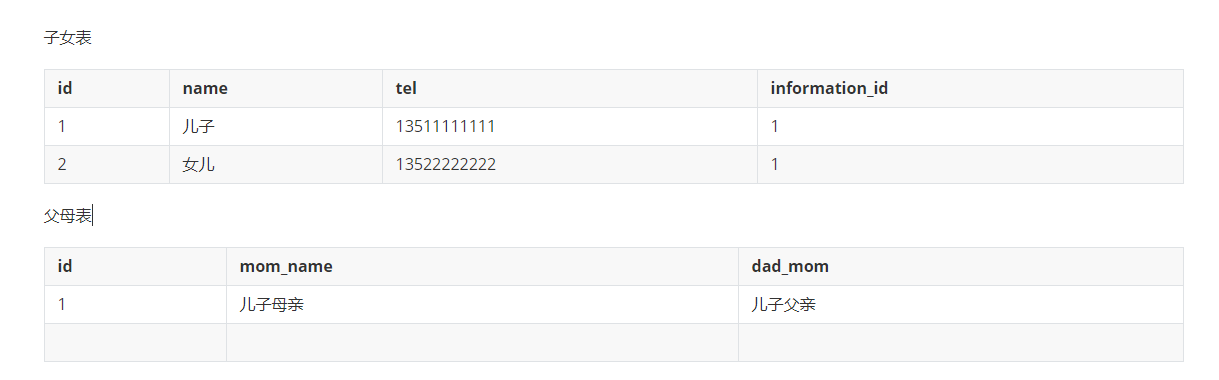
若在父母表中,新增一列时,情景如下:
但这样会有个问题,若新增一个子女,还需要维护父母表中的某个字段,维护起来特别麻烦
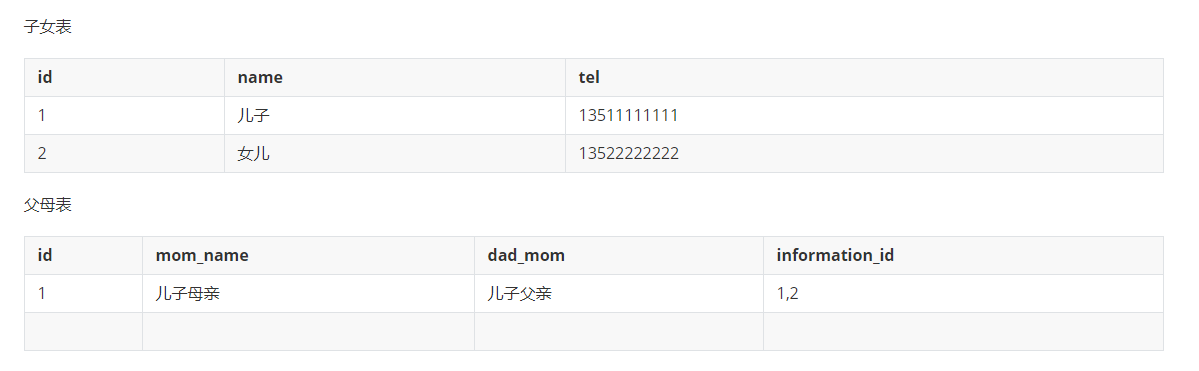
(3)实体A对实体B为多对多:新建一个表C,这个表只有两个字段,一个用于存储A的主键值,一个用于存储B的主键值