一、SQL优化
原因:性能低、执行时间太长、等待时间太长、SQL语句欠佳(连接查询)、索引失效、服务器参数设置不合理(缓冲、线程数)
1、SQL编写过程与解析过程
编写过程:
1 | select distinct ... from ... join .. on .. where .. group by ... having ...order by ... limit ... |
解析过程:
1 | from ... on .... join ... where ... group by ... having ... select distinct ... order by ... limit ... |
2、SQL优化
主要是在 优化索引
索引:相当于书的目录
索引:index是帮助MYSQL高效获取数据的数据结构。索引是数据结构(树:B树(MYSQL默认)、Hash树)
3、索引的优劣势
3.1 优势
- 提高查询效率(降低IO使用率)
- 降低CPU使用率(….order by age desc,因为B树索引 本身是一个排好序的结构,因此在排序时,可以直接使用)
3.2 劣势
- 索引本身很大,可以存放在内存/硬盘(通常为硬盘)
- 索引不是所有情况均适用:(1)少量数据(2)频繁更新的字段(3)很少使用的字段
- 索引会降低增删改的效率(需要维护索引)
4、索引
4.1 索引分类
(1)单值索引:单列,age;一个表可以有多个单值索引,name
(2)唯一索引:不能重复。id,可以是null
主键索引:不能重复。id,不能是null
(3)复合索引:多个列构成的索引(相当于二级目录:z:zhao)(name,age)
4.2 创建索引
4.2.1 方式一
1 | -- 创建表 |
4.2.2 方式二
1 | -- alter table 表名 add 索引类型 索引名(字段) |
注意:如果一个字段是 primary key,则该字段默认就是 主键索引
4.3 删除索引
1 | -- 删除索引: |
4.4 查询索引
1 | --查询索引: |

5、SQL性能问题—explain详解(Mysql 8.0.26)
(1)分析SQL的执行计划:explain,可以模拟SQL优化器执行SQL语句,从而让开发人员 知道自己编写的SQL状况
(2)MYSQL查询优化器会干扰我们的优化
优化方法,官网
查询执行计划:explain + SQL语句
explain select * from tb;

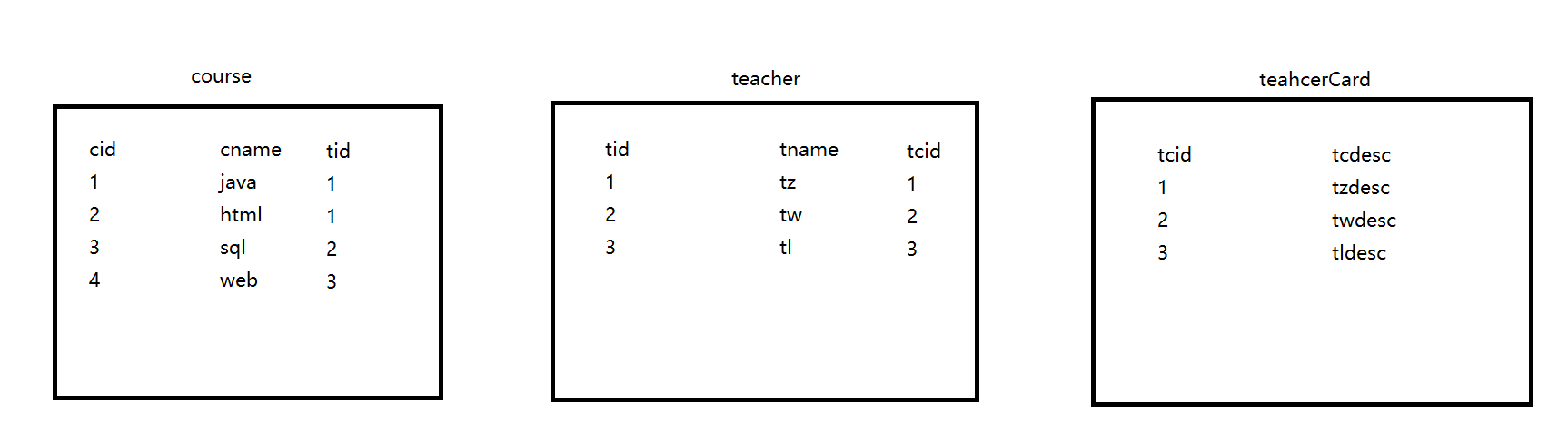
5.1 准备数据
1 | create table course( |
5.2 id 编号
查询课程编号为2 或教师证编号为3的老师信息
(1)id值相同,从上往下,顺序执行
先找t表,然后找tc表,最后找c表(从表结构图中可知:t3-tc3-c4,t表和tc表都是3条数据,course表是4条)
1 | explain select t.* from teacher t,course c,teachercard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3); |

若给teacher表增加一点数据
1 | insert into teacher values(4,'ta',4); |
1 | explain select t.* from teacher t,course c,teachercard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3); |
mysql 5.7.28 执行结果如下
本应该是小表驱动大表原则。但我这未按照t3-c4-tc6来输出,可能MySQL5.6是这个规则
数据小的表,优先查询

(2)id值不同,id值越大越优先查询(本质:在嵌套子查询时,先查内层,再查完成)
查询教SQL课程的老师的描述
1 | explain select tc.tcdesc from teachercard tc,course c,teacher t where c.tid = t.tid and t.tcid = tc.tcid and c.cname = 'sql'; |

(3)id值部分相同,部分不同:(id值越大越优先,id值相同,从上往下,顺序执行)
1 | explain select t.tname ,tc.tcdesc from teacher t,teachercard tc where t.tcid = tc.tcid and t.tid = (select c.tid from course c where cname = 'sql'); |

5.3 select_type 查询类型
5.3.1 PRIMARY
包含子查询SQL中的 主查询(最外层)
5.3.2 SUBQUERY
包含子查询SQL中的 子查询(非最外层)
5.3.3 SIMPLE
简单查询(不包含子查询、UNION)
1 | explain select * from course; |

5.3.4 DERIVED
衍生查询(使用到了临时表)
在from子查询中,如果有table1 union table2,则table1 就是DERIVED,table2就是UNION
1 | explain select cr.cname from (select * from course where tid = 1 union select * from course where tid = 2) cr; |

5.3.5 UNION
见5.3.4
5.3.6 UNION RESULT
就是告知开发人员,哪些表之间存在union查询
5.4 table 表
5.5 type 类型(索引类型)
system > const > eq_ref > ref > range > index > all;
要对type进行优化的前提:有索引
其中:system,const只是理想情况;实际能达到 ref > range;
(1)system(忽略):只有一条数据的系统表;或衍生表只有一条数据的主查询
(2)const:仅仅能查到一条数据的SQL,用于Primary key 或unique索引(类型 与索引类型有关)
1 | create table test01( |
1 | explain select * from test01 where tid = 1; |

若将主键索引修改,则type类型就不会是const
1 | -- 修改索引 |
1 | explain select * from test01 where tid = 1; |

(3)eq_ref:唯一性索引:对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多,不能0)
常见于唯一索引和主键索引
1 | -- 给teachercard表添加主键索引 |
1 | explain select t.tcid from teacher t,teachercard tc where t.tcid = tc.tcid; |
下图中,tc表的type类型不是eq_ref
因为tc表中有6条数据,t表中有3条数据,用tc表查询时,有3条数据的返回值是0,导致不满足条件

1 | -- 删除teacher表中的后3条语句 |

说明:以上SQL,用到的索引是t.tcid,即teacher表中的tcid字段;如果teacher表中的数据个数和连接查询的数据个数一致(都是3条数据),则有可能满足eq_ref级别(数据要保持完全一致),否则无法满足。
- (4)ref:非唯一性索引,对于每个索引键的查询,返回匹配的所有行(0,多)
1 | -- 增加数据 |

(5)range:检索指定范围的行,where后面是一个范围查询(between,in,>,<,>=)
特殊:in有时候会失效,从而转为 无索引all
1 | -- 创建索引 |

- (6)index:查询全部索引中的数据
1 | -- tid是索引,只需要扫描索引表,不需要所有表中的所有数据 |

- (7)all:查询全部表中的数据
1 | -- cid不是索引,需要全表扫描,即需要所有表中的所有数据 |

总结:
- system/const:结果只有一条数据
- eq_ref:结果多条,但是每条数据是唯一的
- ref:结果多条,电脑上每条数据是0或多条
5.6 possible_keys 可能用到的索引
是一种预测,不准
1 | -- 给course表添加一个索引 |

1 | -- 预测使用两个索引,但实际只用到一个 |

5.7 key 实际使用到的索引
5.8 key_len 索引的长度
作用:用于判断复合索引是否被完全使用
1 | create table test_kl( |

1 | alter table test_kl add column name1 char(20); |

1 | -- 删除索引 |
1 | -- key_len = 121,使用的是name1 |

1 | -- key_len = 60,使用的是name |

1 | alter table test_kl add column name2 varchar(20); |

总结:
- utf8:1个字符3个字节
- gbk:1个字符2个字节
- latin:1个字符1个字节
5.9 ref 表之间的引用
注意与type中的ref值进行区分
作用:指明当前表 所参照的字段
1 | select ... where a.c = b.x;(其中b.x可以是常量,const) |
1 | -- t表 是用的'tw'进行比较,是常量,因此是const |

1 | -- 给course的tid添加索引 |

5.10 rows 行
被索引优化查询的数据个数(实际通过索引查询到的数据个数)
1 | -- t表的个数为2 是因为通过判断条件 可以从t表中查询到2个 |

5.11 filtered 后续待学习
5.1.12 Extra 额外信息
- (1)using filesort:性能消耗大;需要“额外”的一次排序(查询)。常见于order by语句
1 | create table test02( |
1 | -- Extra 为空 是因为先对a1 进行查询,然后对a1进行排序 |

1 | -- Extra需要一次额外排序,是因为先对a1进行查询,然后对a2进行排序,所以需要一次额外的排序 |

1 | -- 删除单索引 |
1 | -- 复合索引,列序为a1,a2,a3;但是查询的时候没有用到a2,直接用到a3,跨列使用,因此会出现Using filesort |

1 | explain select * from test02 where a2 = '' order by a3; |

1 | explain select * from test02 where a1 = '' order by a2; |

总结:
- 对于单索引,如果排序和查找是同一个字段,则不会出现 Using filesort;如果排序和查找不是同一个字段,则需要额外一次排序。避免 :where 哪些字段,就order by哪些字段
复合索引,要按照复合索引的顺序使用,不要跨列或无序使用
(2)using temporary:性能损耗大,用到了临时表。一般出现在group by 语句中;已经有表了,但不适用,必须再来一张表(需要额外使用一张表)。
1 | -- 查a1,用a1,但根据a2进行分组,就会出现临时表 |

(3)using index:性能提升;是指索引覆盖(覆盖索引)。
原因:不读取原文件,只从索引文件中获取数据(不需要回表查询)。只要使用到的列全部都在索引中,就是索引覆盖。
1 | -- 例如,test02表中有一个复合索引(a1,a2,a3) |

1 | -- 删除复合索引 |

using index时,会对possible_keys和key造成影响:
如果没有where,则索引只出现在key中
如果有where,则索引出现在key和possible_key中
(4)using where:需要回表查询
假设age是索引列,但查询语句 select age,name from … where age = ….;此语句中必须回原表查Name,因此会显示using where。


1 | explain select a1,a3 from test02 where a3 = ''; |

- (5)impossible where:where子句永远为false
1 | explain select * from test02 where a1= 'x' and a1= 'y'; |

6、SQL优化举例
1 | create table test03( |

1 | explain select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a4=3 order by a3; |

1 | explain select a1,a2,a3,a4 from test03 where a1=1 and a4=3 order by a3; |

1 | explain select a1,a2,a3,a4 from test03 where a1=1 and a4=3 order by a2,a3; |

总结:
- 如果(a,b,c,d)复合索引 和 使用的顺序全部一致(且不跨列使用),则复合索引全部使用。如果部分一致,则使用部分索引
- where 和 order by拼起来,不要跨列
6.1 单表优化
1 | create table book( |
1 | -- 查询authorid = 1 且typeid 为2 或者3的bid |

1 | -- 优化1:加索引,优化后,type由all升级到index了 |

1 | -- 根据SQL实际解析的顺序,调整索引的顺序 |

1 | -- 再次优化 |

小结:
- 索引不能跨列使用(最佳左前缀),保持索引的定义和使用的顺序一致性
- 索引需要逐步优化
- 将含In的范围查询放到where条件的最后,防止失效
本例中同时出现了Using where(需要回原表);Using index (不需要回原表):原因,where authorid = 1 and typeid in (2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中查到),而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表
证明:
2
explain select bid from book where authorid = 1 and typeid =3 order by typeid desc;

6.2 双表优化
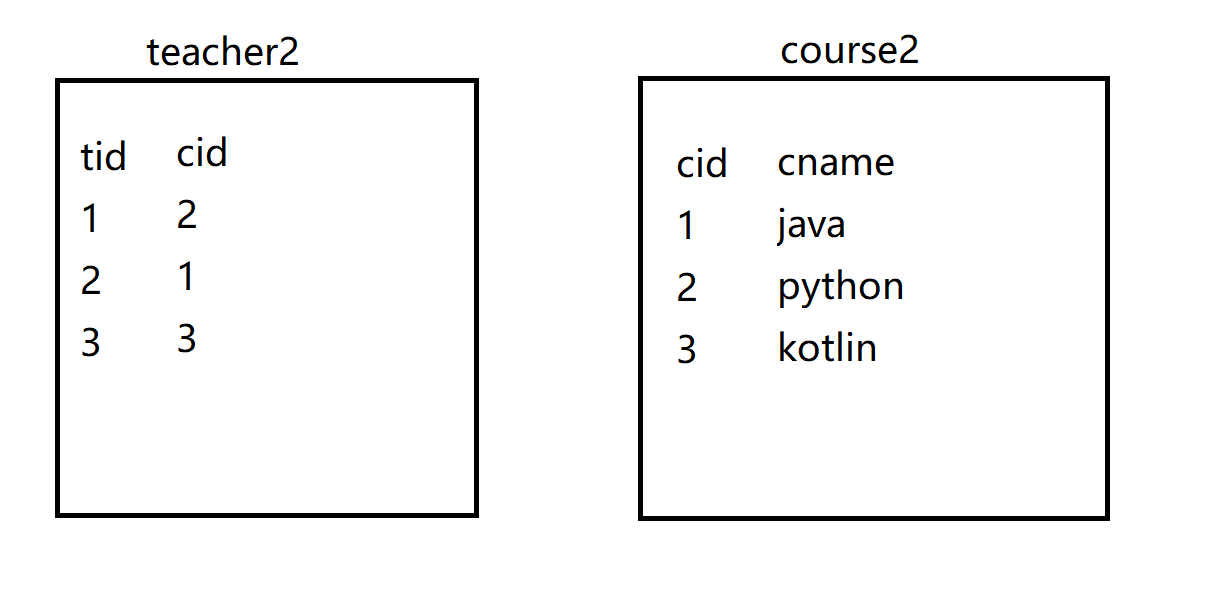
1 | create table teacher2( |

1 | -- 索引该往那张表加?- 小表驱动大表 -索引建立在经常使用的字段上(本题t.cid=c.cid可知,t.cid字段使用频繁,因此给该字段添加索引)【一般情况对于左外连接,给左表加索引;右外连接,给右表加索引】 |

1 | alter table teacher2 add index index_teacher2_cid(cid); |

1 | alter table course2 add index index_course2_cname(cname); |

6.3 三表优化
- 小表驱动大表
- 索引建立在经常查询的字段上
7、避免索引失效的一些原则
复合索引,不要跨列或无序使用(最佳左前缀)
复合索引,尽量使用全索引匹配(a,b,c,尽量全部使用)
不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
2
3
4
select ... where A.x = ... ; -- 假设A.x是索引
-- 不要:select ... where A.x * 3 = ...;
explain select * from book where authorid = 1 and typeid = 2;
2
explain select * from book where authorid = 1 and typeid * 2 = 2;
2
explain select * from book where authorid * 2 = 1 and typeid * 2 = 2;
2
3
-- 原因:对于复合索引,如果左边失效,右侧全部失效。(a,b,c),例如如果b失效,则b,c同时失效
explain select * from book where authorid * 2 = 1 and typeid = 2;
索引不能使用不等于(!= 、<>)或 is null (is not null),否则自身会失效
2
3
4
5
6
7
8
alter table book add index idx_authorid(authorid);
alter table book add index idx_typeid(typeid);
-- SQL优化,是一种概率层面的优化。至于是否实际使用了我们的优化,需要通过explain进行预测。
-- 比如下列explain + SQL,和我们认为的一样,预测的索引是authorid和typeid,但实际使用的只是authorid
-- 因此长度为4
explain select * from book where authorid = 1 and typeid = 2;
2
explain select * from book where authorid != 1 and typeid = 2;
补救:尽量使用索引覆盖(usintg index);
like尽量以“常量开头”,不要以’%’开头,否则索引失效
2
explain select * from teacher where tname like '%x%';-- tname索引失效
2
explain select tname from teacher where tname like '%x%';
尽量不要使用类型转换(显示、隐式),否则索引失效
2
3
-- 程序底层将 123 ->'123'
explain select * from teacher where tname = 123;
尽量不要使用or,否则索引失效
2
explain select * from teacher where tname = '' or tcid > 1;
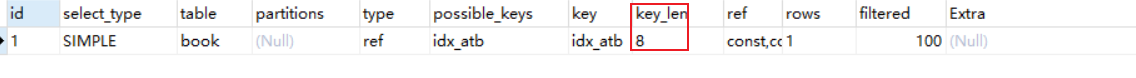










8、一些其他的优化方法
(1)exist 和in
exist语法:将主查询的结果,放到子查询中进行条件校验(看子查询是否有数据,如果有数据,则校验成功),如果符合校验,则保留数据
2
3
-- 如果select * from teacher有数据,等价于下面的
select tname from teacherin:
2
select ... from A where id in (select id from B);
如果主查询的数据集大,则使用in,效率高
如果子查询的数据集大,则使用exist,效率高
(2)order by 优化
using filesort有两种算法:双路排序、单路排序(根据IO的次数)
MySQL4.1之前,默认使用双路排序;双路:扫描2次磁盘(第一次扫描排序字段,对排序字段进行排序(在buffer中进行的排序)。第二次扫描其他字段) — IO比较消耗性能,因此后续采用单路排序
MySQL4.1之后,默认使用单路排序:只读取一次(全部字段),在buffer中进行排序,但该单路排序,会有一定的隐患(不一定真的是“单路|一次IO”,有可能多次IO)— 若数据量过大,则无法将所有字段的数据一次性读取完毕,因此会进行“分片读取,多次读取”。
注意:单路排序比双路排序会占用更多的buffer。单路排序在使用时,如果数据大,可以考虑调大Buffer的容量大小:
如果max_length_for_sort_data 值太低(太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数),则MySQL会自动从 单路->双路。
提高order by查询的策略:
- 选择使用单路、双路,调整buffer的容量大小
- 避免使用select * ……
- 复合索引,不要跨列使用,避免using filesort
- 保证全部的排序字段,排序的一致性(都是升序或降序)
9、SQL排查—慢查询日志
MySQL提供的一种日志记录,用于记录MySQL提供的一种日志记录,用于记录MySQL中响应时间超过阈值的SQL语句(long_query_time,默认10秒),慢查询日志默认是关闭的;建议:开发调优时打开,最终部署时关闭。
检查是否开启了慢查询日志:
临时开启
2
show variables like '%slow_query_log%';
临时设置阈值
2
set global long_query_time = 5; -- 设置完毕后,重启登录生效(不需要重启服务)
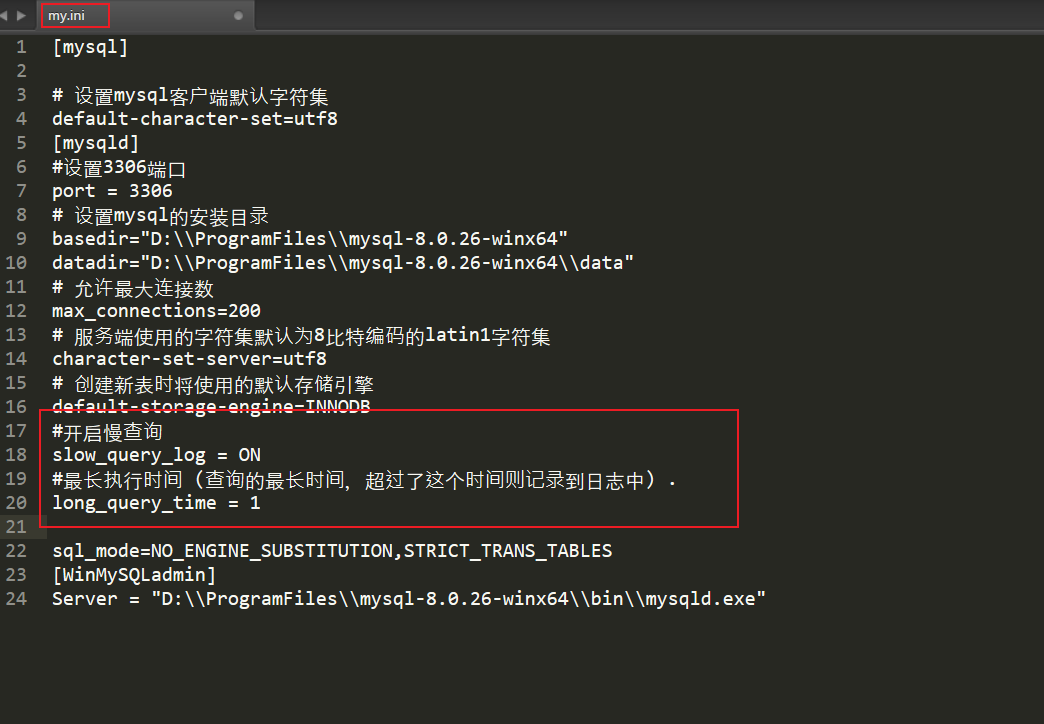
永久开启:Windows下在mysql安装目录的my.ini中添加修改



10、模拟分析海量数据
10.1 模拟海量数据
存储过程(无return)/存储函数(有return)
1 | create database testdata; |
插入数据
1 | call insert_emp(1000,800000); |
10.2 分析海量数据
(1)profiles;
1 | show profiles; -- 默认关闭 |
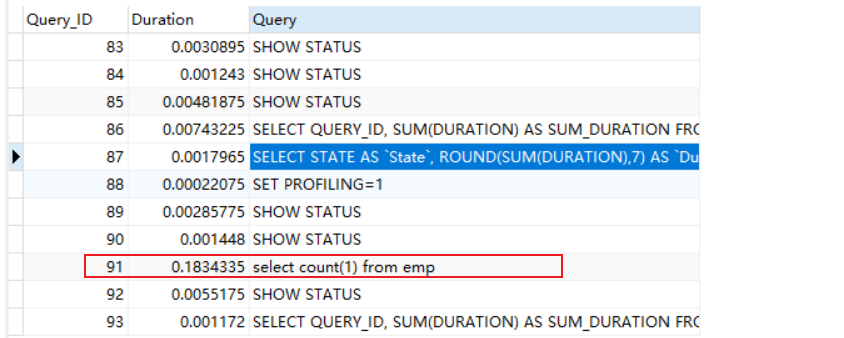
(2)-精确分析:sql诊断
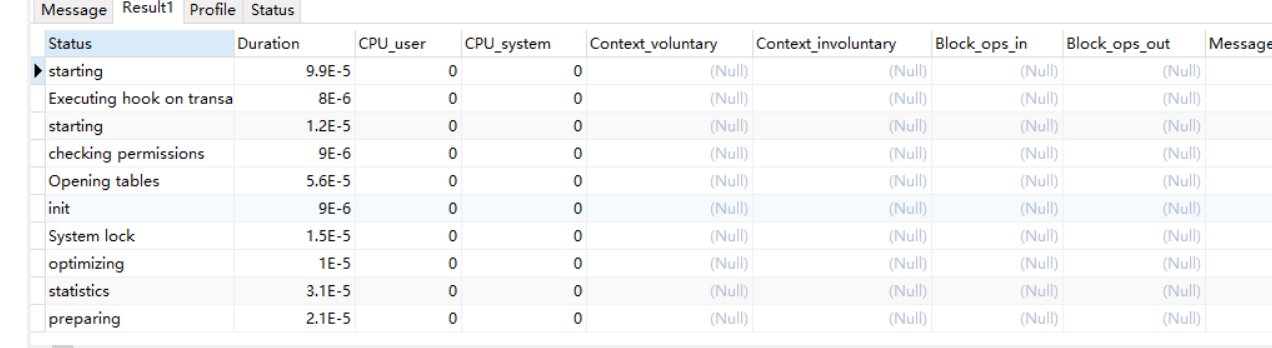
1 | show profile all for query 91; |
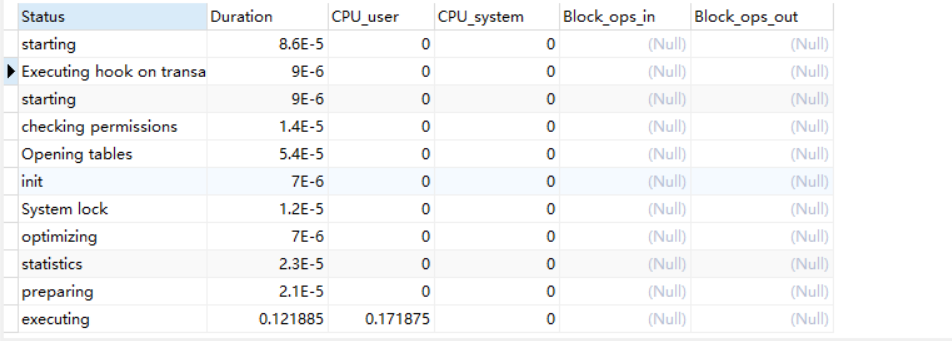
1 | show profile cpu,block io for query 91; |
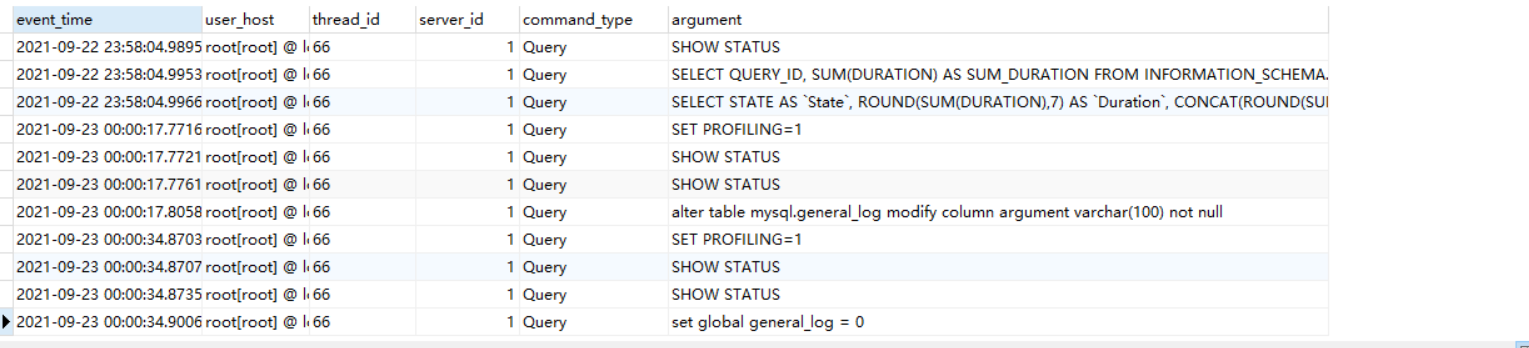
(3)全局查询日志:记录开启之后的全部SQL语句(这次全局的记录操作,仅仅在调优、开发过程中打开即可,在最终的部署实施时一定要关闭)。
1 | show variables like '%general_log%'; |

1 | set global general_log = 1; --开启全局日志 |
1 | alter table mysql.general_log modify column argument mediumtext not null; -- 修改argument的类型 |